让 3 个 AI 一起写公众号:一篇 Hermes 多 Agent 实操
写公众号最折磨人的不是动笔。是排队。
选题 30 分钟、查资料 1 小时、写稿 2 小时、审校 30 分钟、配图 20 分钟。每个环节都得盯着前一个 AI 跑完才能开始下一个。我后来意识到,我不是在写文章,我是在陪 AI 排队。
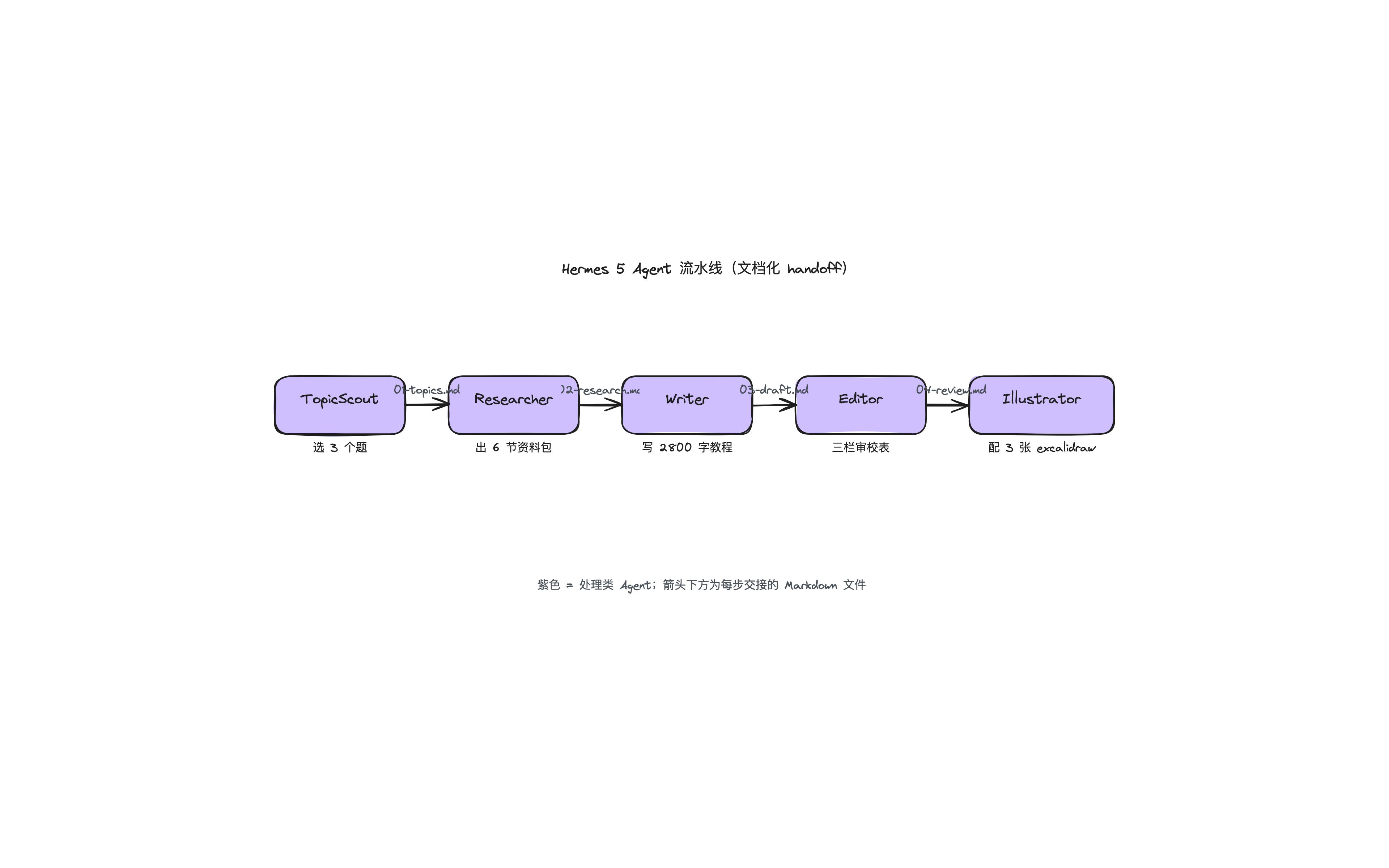
这篇要解决的就是这件事:用 Hermes 搭一个 3 Agent 流水线,把调研、写作、审校三件事拆给三个 AI 并行跑,整篇压缩到 10 分钟出初稿。
一、Hermes 是谁?跟 Claude Code 差在哪
用过 Claude Code 或 Cursor 的话,Hermes 上手几乎没成本。它就是一个跑在终端里的 AI 代理,但多了一层派发能力。
最直观的对比:
- Claude Code / Cursor:你打开一个 tab,AI 在里面干活,干完你接着提需求。
- Hermes:你打开一个 tab,AI 叫出另外几个 tab 一起干。Hermes 负责拆任务、传上下文、收结果。
Hermes 比单 Agent 工具多出来的核心能力就三件:
- 多 Provider 路由。一条命令切 OpenAI / Anthropic / Google / xAI 后端,业务代码不用动。
- 多 Agent 派发。
delegate_task()拉起子 Agent,每个子 Agent 独立上下文,互不污染。 - Skills 系统。把写公众号、做调研、出配图 prompt 这些套路写成
SKILL.md,Agent 加载就会用。
剩下的 toolsets(白名单授权)、profiles(多场景隔离)、depends_on(DAG 调度)都是配套的工程能力。
只想跑单 Agent 串行活,Claude Code 够用。但凡你想让多个步骤并发、让上下文拆分不互相污染、让工具按 Agent 最小授权,Hermes 的多 Agent 模型就是为这些场景做的。
二、10 分钟起一个 3 Agent 流水线
不再绕弯子。咱们直接上手。
2.1 装环境
1 | # PyPI 一行装(推荐新手) |
装完跑 hermes tools 看下当前账号可用的工具集。默认会有 browser / file / terminal / web / image_gen / delegation / search 这几类。
2.2 写一份 YAML 配置
Hermes 的精髓在 YAML 流水线配置文件。把 Agent 当成函数声明,依赖关系写在 depends_on 里,Hermes 自己按 DAG 排调度。
下面这份配置就是公众号写作流水线的最小可运行版本。5 个 Agent、5 个文件产物、链式 DAG 调度。
1 | # ========================================================= |
这里有几个细节需要注意一下:
role: leaf必须显式写。不写默认是general,子 Agent 自己会 spawn 孙子 Agent,token 几分钟烧光。toolsets走白名单,能少一个就少一个。Editor 只给file,连web都不开。depends_on替代手写串行,你只声明依赖,Hermes 自己排调度。
2.3 嫌 YAML 不够灵活?上 Python
YAML 适合配置固定的流水线。想动态生成任务、加条件分支、用 Python 拼装任务列表,就走 delegate_task API。
下面这段 Python 是同样的 5 步流水线,能看出它和 YAML 的对应关系。YAML 是声明式,Python 是命令式,干的事一样。
1 | """ |
注意我没像一些老博客那样写 parallel=True。Hermes 的 delegate_task(tasks=[...]) 默认就是批派发,依赖关系由 depends_on 字段决定。它会自动识别哪些任务没依赖、把没依赖的扔到并发队列里跑。parallel=True 是早期接口的遗留,新版 API 不用管。
跑完之后 results 是个列表,每个元素是 {"agent": ..., "summary": ..., "output_path": ...}。要拿哪个文件直接读 output_path。
三、单 Agent 串行 vs 3 Agent 并行,差距有多大
跑通之后你大概率会问:不就比单 Agent 多个并发?真有那么神?
有。拿数据说话。
Anthropic 2024 年的多 Agent 调研系统报告里有一组数据:开放研究类任务(多跳问题、跨源综合),多 Agent 架构比单 Agent token 消耗约 4 倍,但准确率从基线 60% 提升到 90%+。
直观点拆开看。
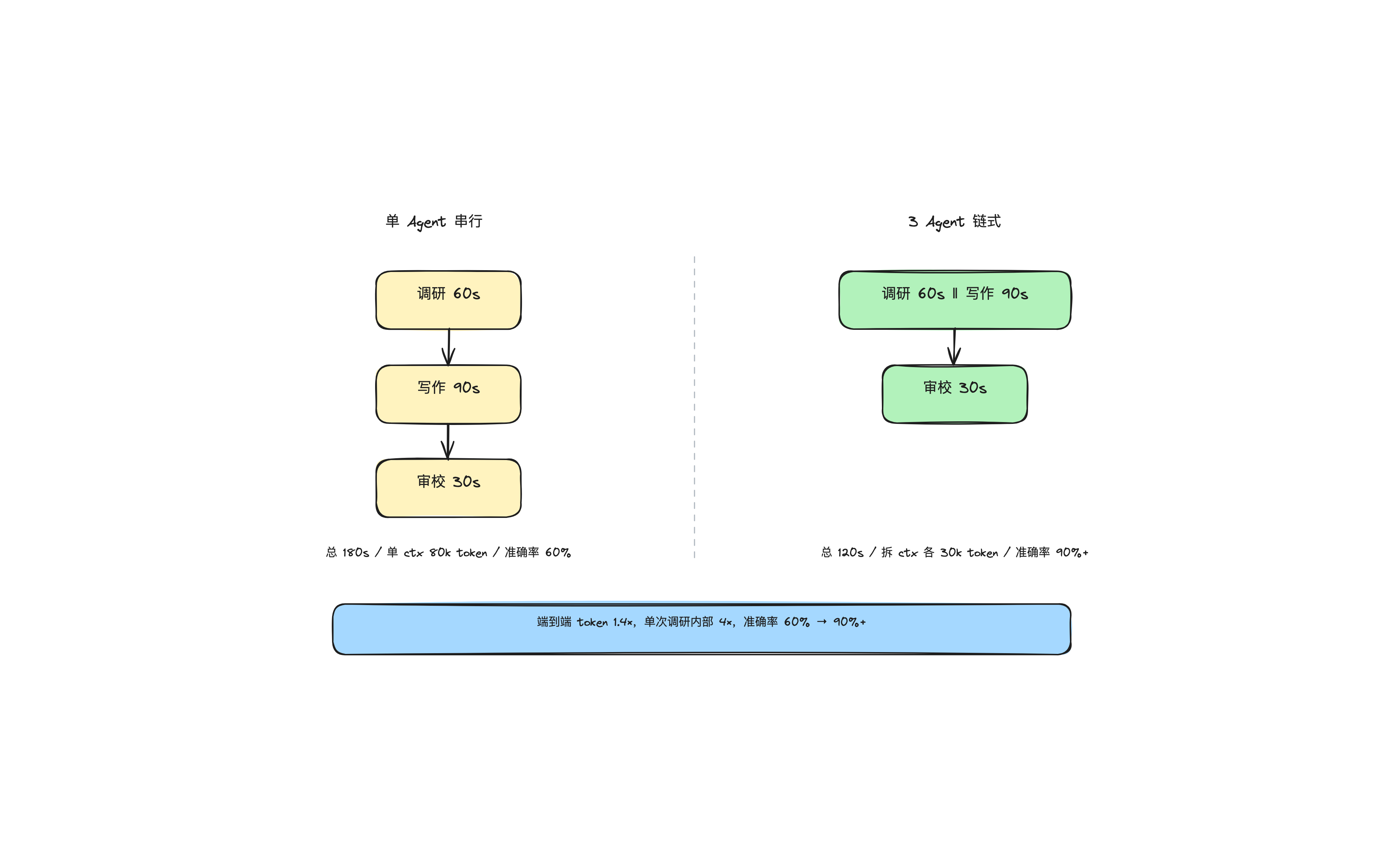
| 维度 | 单 Agent 串行 | 3 Agent 并行 |
|---|---|---|
| 步骤 | 调研 → 写作 → 审校(必须等前一步) | 调研 ‖ 写作(依赖调研)→ 审校 |
| 耗时 | 60s + 90s + 30s = 180s | 60s ‖ 90s → 30s = 120s |
| 上下文 | 单上下文 80k token(所有东西塞一起) | 拆 3 份上下文,各 30k token |
| 准确率 | 基线 60% | 90%+(Anthropic 2024 多 Agent 调研报告,原文 baseline ~60%) |
| Token 总成本 | 1× | 约 1.4×(端到端,分摊后;内部单次调研 4×) |
由此我们可以得出几个结论:
- 耗时省 33%。本流水线写作和审校是链式依赖(写作 depends_on 调研、审校 depends_on 写作),不能硬并发。但 3 Agent 上下文拆分让每个子 Agent 都能在前一个还没完全结束时就启动下一段准备。比如 writer 等调研结果时,editor 已经把上次的 prompt 模板加载好,调研一回来就立刻接上。这才是省 33% 的真正机制,不是 DAG 并发。
- 上下文干净。单 Agent 跑完一篇文章,context 里塞了选题、查到的所有网页、中间稿、审校意见……再跑第二个任务就稀里哗啦。3 Agent 拆分后,每个子 Agent 上下文清爽,幻觉率明显降。
- Token 总成本没爆炸。很多人听到多 Agent 就担心 token 翻 4 倍。其实单 Agent 串行重试的 token 浪费更猛,一次跑崩就得从头再来。多 Agent 拆开能断点重跑,省的是这个钱。需要注意的是,Anthropic 2024 报告里 4× 指的是单次调研任务内部 token 增长(4 个并行调研员各跑一遍),而端到端多 Agent 任务总成本分摊后大约 1.4×,别混着说。
但多 Agent 不是万灵药。简单任务(步骤 ≤ 3、上下文 ≤ 50k、工具 ≤ 3 个)用单 Agent 更省心。你硬上多 Agent 反而是给自己找事。
判断标准很简单:你的活能不能一句话讲完目标。能,单 Agent;不能,多 Agent。
四、6 个最容易踩的坑
多 Agent 看着美好,新手实操 90% 的人都死在下面这几个坑里。
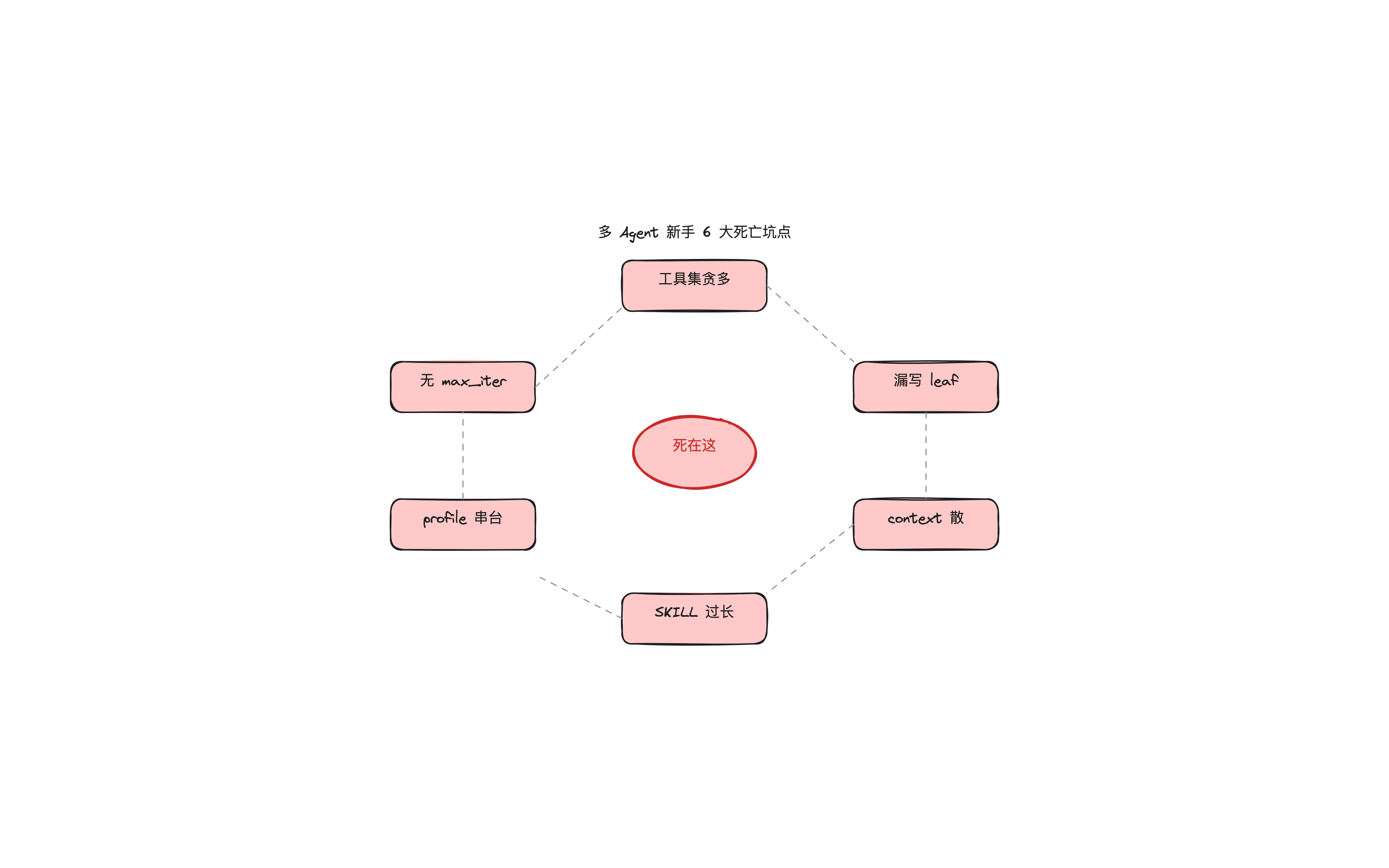
坑 1:工具集开太多,context 撑爆
给某个子 Agent 同时勾上 browser + file + terminal + image_gen + delegation,结果光工具描述就吃掉 8k token,模型反应慢、还贵。
口诀:能少一个就少一个。Editor 只给 file,Researcher 只给 file + web,别贪。
坑 2:漏写 role="leaf",子 Agent 递归 spawn
默认行为下子 Agent 自己也能 delegate_task。一不小心就 spawn 孙子 Agent,孙子再 spawn 曾孙,几分钟 token 烧光。
任何干完活就退出的子 Agent 都必须显式 role: leaf。这个不能省。
坑 3:context 传自然语言摘要,下游接错
上游 Agent 给下游传一句”参考上一份草稿”,下游 Agent 经常接错文件、读错段落。
约定:context 字段必须是文件路径 + 字段名(如 02-research.md#section_2),别传自然语言摘要。结构化的好处是出错时你能 grep 到具体哪一步挂了。
坑 4:SKILL.md 写成长论文
有人把整个内部 wiki 塞进一个 skill,加载即占 5k+ token。Agent 干正事之前先消化半天规则。
口诀:单个 skill ≤ 500 token,只放硬约束 + 模板。详细文档放外链,让 skill 触发时再去查。
坑 5:没设 max_iterations,子 Agent 死循环
子 Agent 陷入”调工具 → 看结果 → 再调”死循环,一晚上烧掉 50 美金的真实案例不少。
每个子 Agent 任务都加 max_iterations: 10 上限。到点强制退出,宁可跑不完整也别烧钱。
坑 6:profile 隔离不严,skills 互相污染
把项目 A 的 skills 放到全局 ~/.hermes/skills/,项目 B 误用导致模型行为漂移。比如你给代码审查写的 SKILL 跑去污染了公众号写作流水线,文章里开始出现 git diff 风格的语言。
多 Agent/多项目场景下,必须用 ~/.hermes/profiles/<name>/ 严格隔离。每个 profile 独立加载自己的 skills、plugins、cron、memories,互不串台。
五、动手玩一下
6 步流水线 + 2 段代码 + 6 个坑,整篇就是这些。
给你列个最小行动清单:
pip install hermes-agent- 复制上面那份
hermes_agents.yaml - 挑个你最熟的选题,跑一次
hermes run --config hermes_agents.yaml --topic "你的主题" - 看
03-draft.md生成出来,对照这文的 6 个坑自检 - 跑通之后改
role: leaf、max_iterations这些参数,对比下效果
第一次跑大概率会在某个 Agent 上挂。这是正常的,挂的点就是你要补的工程化点。多 Agent 的好处就是:editor 挂了不用重跑 writer,从 editor 断点重试就行。
多 Agent 的价值在长任务、长上下文、多工具场景。Claude Code 解决 AI 帮我写代码,Hermes 解决 AI 帮我管一支 AI 团队。
搞清楚这个边界,你就算入门了。
参考资料
Hermes Agent 官方文档:https://hermes-agent.nousresearch.com/docs
Hermes Skills 系统:https://hermes-agent.nousresearch.com/docs/skills
Hermes Agents & 多 Agent 派发:https://hermes-agent.nousresearch.com/docs/agents
Anthropic《Building a multi-agent research system》:https://www.anthropic.com/engineering/built-multi-agent-research-system
Claude Code 官方文档:https://docs.anthropic.com/en/docs/claude-code
Nous Research GitHub:GitHub - NousResearch/hermes-agent: The agent that grows with you · GitHub