从零学习Kafka:调优
在这个系列的结尾篇,我们来聊一下 Kafka 有哪些调优策略。
调优目标
在开始之前,我们先明确一下调优的目标:对 Kafka 来说,通常是在高吞吐、低延迟、高可靠这三点之间找到一个平衡。
吞吐量就是 TPS,指的是 Broker 端进程或者 Client 端程序每秒能处理的字节数或消息数。这个值是越大越好,也就是我们期望的高吞吐。
延迟通常是指消息从 Producer 端生产到 Consumer 端成功消费的总时长。这个值我们希望的越短越好,我就是低延迟。
可靠性从两个方面理解,一是集群整体的稳定性,也就是集群会不会出现不可用的情况,这点毋庸置疑,我们一定是希望稳定性越高越好的。另一方面是消息传输的稳定性,也就是会不会丢消息,在某些场景下,我们可能会舍弃一部分消息传输的可靠性来换取高性能。
调优分层
明确了目标之后,我们把调优的方法按照层级进行划分。
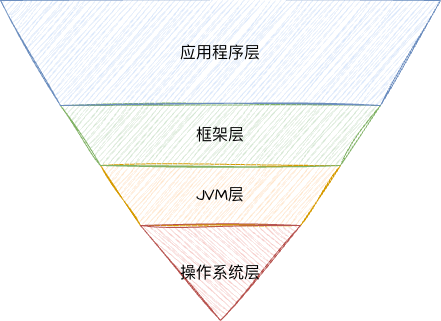
我们分为 4 层,总的来说,越靠上的层级调优效果越好。
应用程序层:指的是我们客户端的代码,即消息的生产和消费逻辑。这些逻辑的优化效果是非常可观的,通常也比较简单。
框架层:在这一层我们通常会调整 Kafka 的各种参数,相对也比较简单。
JVM 层:指的是 Broker 端的 JVM 调优,针对 JVM 的调优也能收获不错的效果。
操作系统层:通常就是 Broker 端部署的操作系统环境的优化。
接下来我们就看一下这 4 个层面分别可以做哪些优化。
应用程序层
我们先来看应用程序层,这部分优化可以认为是最简单,也是最有效的。但由于每个业务甚至每个开发者写出来的逻辑都不一样,对应的优化方法也不一样。因此我无法给出一个“银弹”。不过有一些最基本的准则需要遵循。
不要频繁创建 Producer 和 Consumer 实例。
用完及时关闭,Producer 和 Consumer 对象底层会使用很多物理资源,不及时关闭的话可能会造成资源泄漏。
合理使用多线程提升性能。
框架层
框架层可做的调优比较多,最基本的就是保持客户端与 Broker 端的版本一致。相同版本的客户端和 Broker 端之间通信可以享受 Zero Copy 的性能收益。
接着我们再分别看一下 Producer、Broker 和 Consumer 三部分还有哪些调优操作。
Producer
首先是生产者,它的瓶颈通常在于 CPU 或网络 IO。调优主要从批量发送、压缩算法和确认机制这三方面入手。
批量发送
批量发送是调优吞吐量的关键,主要是调整 batch.size 和 linger.ms 这两个参数。其实在前面的文章中我们也有提到过。
如果想要高吞吐,可以适当调大这两个参数的值。例如 batch.size 可以从默认的 16KB 调大到 512KB 或者 1MB,linger.ms 可以调整到 10 到 100 毫秒。
如果想要低延迟,我们可以调小这两个参数,最极端的方式是 linger.ms 设置为 0,也就是数据不在 Producer 端停留,直接发出去。
压缩算法
压缩可以节省网络 IO,但会消耗 CPU 资源。这部分在从零学习Kafka:生产者压缩一文中有详细的介绍。
如果需要高吞吐,推荐使用 lz4 或 zstd 算法。
如果需要低延迟,就不要开启压缩。
确认机制
主要调整 acks 参数。这是性能与可靠性的平衡。
想要高性能,可以设置 acks=1,即 Leader 收到后就返回。
想要高可靠,可以设置 acks=all,确保所有副本都同步到消息。
Broker
再来看 Broker 端的调整。
首先是 num.replica.fetchers 参数,它用来控制 Follwer 副本用多少个线程来拉取消息。不论是高吞吐还是低延迟的场景,最好都把这个参数调大一点,但不要超过 CPU 核数。
然后是内存层面,Kafka 强依赖操作系统的页缓存,因此不要给 Broker 配置太大的 JVM 堆内存,通常配置 6 到 10 GB 足够用,剩下的留给页缓存。
接着到磁盘层面,log.dirs 可以配置多个磁盘路径,Kafka 会在这些路径间分布分区,这样可以有效利用多块磁盘的并非 IO 来提升性能。
最后到网络层面,num.network.threads 参数用来指定接收请求的线程数,num.io.threads 参数用来指定处理磁盘请求的线程数,这两个参数都可以适当调大。
Consumer
最后我们来看消费者端的调优。消费者端有两个核心参数:fetch.min.bytes 和 fetch.max.wait.ms。fetch.min.bytes 代表单次抓取的最小数据量,fetch.max.wait.ms 代表如果数据量不够,最长的等待时长。
如果是高吞吐场景,可以调大这两个参数。相反,如果是低延迟场景,可以调小这两个参数。
我们通过一个表格来小结一下。
| 场景 | 核心参数 | 适用业务 |
|---|---|---|
| 高吞吐 | 调大 batch.size 和 linger.ms,压缩算法使用 lz4 或 zstd |
日志收集类场景 |
| 低延迟 | linger.ms 设置为 0,acks 设置为 1 |
实时监控告警 |
| 高可靠 | acks=all 和 min.insync.replicas 至少是 2 |
金融支付等场景 |
至此,框架层的调优方法就介绍完了,我们继续顺着漏斗往下看。
JVM 层
Kafka 的 JVM 层的调优和其他服务的 JVM 调优没什么区别。除了我们刚刚提到的不要设置太大的堆内存之外,就是要选择合适的垃圾回收器,最好使用 G1 和 ZGC 这样更先进的垃圾回收器,不光性能更好,调优方法也会简单很多。
操作系统层
操作系统层的调优可能大部分同学不会接触到,这里我们简单介绍几个方法。
第一是在挂载文件系统时执行下面的命令禁用掉 atime 更新,这一调整可以减少文件系统的写操作数。
1 | mount -o noatime |
第二是选择合适的文件系统,可以是 ext4 或 XFS。当然如果有性能和可靠性更好的文件系统也可以尝试。
总结
最后我们来总结一下本文的内容,我们首先明确了 Kafka 调优的目标,即在高吞吐、低延迟、高可靠三点中找到平衡。接着对调优方法进行了分层,从上到下分别是应用程序层、框架层、JVM 层和操作系统层,通常越靠上调优效果越好。这四层中我们重点介绍了框架层的调优方法。
到这里从零学习 Kafka 系列就完结了,感谢各位读者一路以来的支持。