从零学习Kafka:ZooKeeper vs KRaft
在 Kafka 的演进史中,抛弃 ZooKeeper 模式,拥抱 KRaft 模式这一变化被认为是其架构上最重要的一次变革。本文我们就来讨论 Kafka 为什么要抛弃 ZooKeeper,以及 KRaft 的设计思路。
为什么抛弃 ZooKeeper
在传统的 Kafka 架构中,Kafka 将元数据管理的责任交给了 ZooKeeper,ZooKeeper 存储了 Topic 列表、分区位置、ISR 列表等信息,为 Kafka 提供了一个可靠的分布式协调服务。集群中的一个 Broker 会被选为 Controller,Controller 负责管理分区副本状态,处理分区重平衡。
随着 Kafka 的发展,对于 ZooKeeper 的重度依赖也带来了一些问题。
元数据同步瓶颈
当 Controller 变更时,它需要从 ZooKeeper 加载完整的集群元数据,然后把这些数据同步给所有的 Broker,对于分区数量很大的集群,这个过程会很长,从而导致整个集群的服务终端。
一致性风险
在 ZooKeeper 模式下,集群本质上存在两个权力中心(ZooKeeper 和 Kafka Controller),它们之间的数据同步延迟会带来一致性问题。我们来看一个具体的场景。
假设我们现在有一个三台 Broker 的集群,分别为 Broker0,Broker1,Broker2,Broker0 为当前 Controller。
在某一时刻,当 Broker0 突然遇到了长时间 Full GC 时,由于 ZooKeeper 长时间没有收到 Broker0 的心跳消息,判断 Broker0 宕机,于是就删除了 /controller 临时节点,然后将 Broker1 选为新的 controller。这时 Broker0 从 GC 中恢复,此时它可能还没有意识到自己已经不是 Controller了,这就会导致集群中存在两个 Controller。假设有一个 Topic 原本的 Leader 是 Broker2,此时 Broker0 和 Broker1 都会给 Broker2 发送指令,下令把分区 Leader 切换到自己。这就会带来比较严重的影响,即一部分 Producer 会把数据写到 Broker0,另一部分 Producer 把数据写到 Broker1。直接导致数据混乱,同时 Consumer 也不知道要消费哪个 Broker 的数据。
运维复杂性
第三个问题就是运维复杂性,ZooKeeper 属于一个独立的组件,如果选择 ZooKeeper 模式,运维人员就需要维护两套系统(Kafka + ZooKeeper),大幅提升了运维复杂度。
基于以上问题,Kafka 社区决定放弃 ZooKeeper,发展内部的共识协议 KRaft。
引入 KRaft
抛弃 ZooKeeper 之后,Kafka 演进到了 KRaft(Kafka Raft)模式,这是一种 Kafka 内部的共识协议,它可以让 Kafka 实现自我管理。
架构
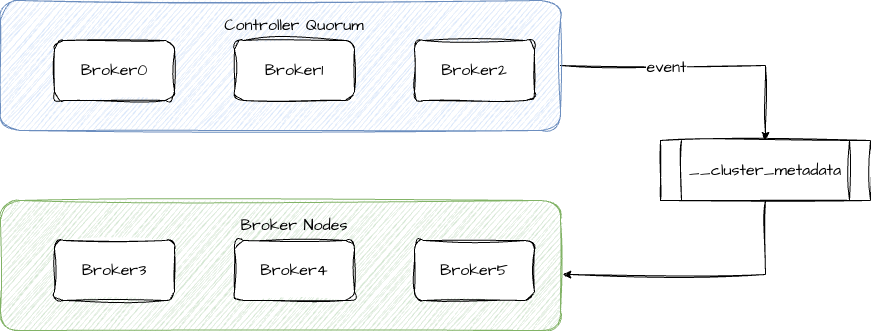
KRaft 模式下,Broker 有两种角色,一种是 Controller Quorum,另一种是 Broker Nodes,可以在配置文件中通过 process.roles 参数来指定 Broker 的角色。Controller Quorum 通常由 3 个或 5 个 Broker 组成,它们之间会选举出来一个作为 Leader。
对于元数据的存储,KRaft 维护了一个内部 Topic __cluster_metadata,所有的集群变更都会作为一条条消息写入到这个 Topic 中,集群内的其他 Broker 通过消费这个 Topic 的消息来感知集群变更。Broker Nodes 节点作为业务节点,只负责数据的读写。
部署方式
KRaft 模式下有两种部署方式,一种是混合模式,一种是隔离模式。
混合模式是指同一个进程即是 Broker,又是 Controller,即 process.roles=broker,controller。这种模式一般适合小型集群或者测试环境。
隔离模式是指 Broker 和 Controller 运行在不同的服务器,这样 Controller 就不会受到大流量的影响,整个集群会更加稳定。在配置时,一部分节点配置为 process.roles=broker,另一部分配置为 process.roles=controller 即可。
为什么解决了问题
我们重点看一下 KRaft 模式为什么解决了前面提到的一致性问题。最直观的一点就是 KRaft 模式下权力中心合二为一,避免了出现多个 Leader 的情况,Controller Quorum 选举的每一任 Leader 都有一个唯一的 Epoch。在向 __cluster_metadata 主题写入指令时会带有自己的 Epoch,其他 Broker 消费到指令时,只认 Epoch 最大的指令。
总结
最后我们以一张表格来对比一下 ZooKeeper 和 KRaft 两种模式。
| 特性 | ZooKeeper 模式 | KRaft 模式 |
|---|---|---|
| 外部依赖 | 需要部署 ZooKeeper 集群 | 无 |
| 元数据存储 | 存储在 ZooKeeper 中 | 内部 Topic |
| Leader 选举 | 依赖 ZooKeeper 协调 | 基于 Raft 协议选举 |
| 元数据更新 | Controller 广播给 Broker | Broker 主动消费 |
| 分区上限 | 受限于 ZK,约 20 万左右 | 可以支撑 100 万+分区 |
| 恢复时间 | 较长 | 极短 |
基于以上对比,我们还了解了依赖 ZooKeeper 为 Kafka 带来的性能瓶颈、一致性问题、以及运维复杂度的提高。在新版本的 Kafka 中,已经全面拥抱 KRaft 了。当然,Kafka 弃用 ZooKeeper 并不代表 ZooKeeper 一无是处,每个系统都有适合自己的应用场景,在合适的场景应用合适的系统才是正确的选择。