从零学习Kafka:位移与高水位
还记得上一篇文章最后的问题吗,什么是 LEO(Log End Offset)?它其实是 Kafka 位移相关的一个核心概念,本文我们就从位移开始,把相关的概念理清楚。
什么是 Offset
我们从 Offset 说起,它是一个单调递增的 64 位整数,当 Producer 把数据写到 Partition 后,Kafka 先为消息分配一个编号,然后再写入到文件中。这个编号就是 Offset,它就像我们去银行办业务,每个人都会拿一个号,后面的人的号总是比前面的大 1,每个人的号都是唯一的。
LEO 和 HW
了解了什么是 Offset 之后,我们再一起来认识今天的两位主角:LEO 和 HW。
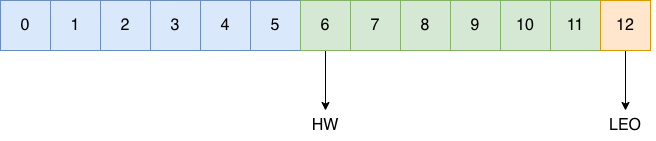
LEO 是 Log End Offset 的缩写,也就是日志末端位移,它表示副本写入下一条消息的位移值。上图中一共有12条消息(位移值为 0 到 11),下一条消息的位移值就是 12,也就是当前副本的 LEO 为 12。
HW 是 High Watermark的缩写,也就是高水位。它用来定义消息的可见性,即哪些消息是可以被消费的。Offset 小于高水位的消息都是已提交消息,是可以被消费的。大于等于高水位值的消息都是未提交消息,这些消息不能够被下游消费。
一个分区的每个副本都会有一组 HW 和 LEO 值,分区的消息是否可以被消费取决于 Leader 副本的高水位值,也就是说,Leader 副本的高水位值就是分区高水位值。这里就会引出另一个问题,Follower 副本与 Leader 副本如何同步高水位和 LEO 值呢?
存储结构
在了解高水位的同步流程之前,我们先看一下 LEO 和 HW 的存储。
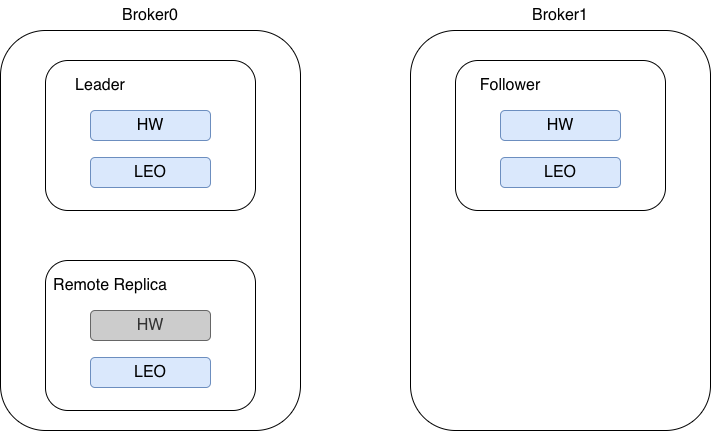
在 Broker0 中,保存了某个分区 Leader 副本的 HW 和 LEO 值,以及这个分区所有的 Follower 副本的 LEO 值,这些 Follower 副本我们称之为远程副本,即 Remote Replica,它们的作用是帮助 Leader 副本确定 HW 值。在 Broker1 中,保存了 Follower 副本的 HW 和 LEO 值。
同步流程
了解了存储结构之后,我们来分别从 Leader 和 Follower 副本的视角看一下它们更新 HW 和 LEO 的具体流程。
首先看 Leader 副本的更新流程,这里分为两个场景,一个是处理生产者的请求逻辑,另一个是处理 Follower 副本的拉取逻辑。
处理生产者请求逻辑如下:
收到 Producer 数据,写入到本地。
更新分区 HW 值。
处理 Follower 副本拉取逻辑如下:
读取磁盘或缓存中的数据。
使用 Follower 副本请求中的位移值更新远程副本的 LEO 值。
更新分区 HW 值。
上面两个场景的核心步骤是更新分区 HW 值,具体的流程是先获取 Leader 副本所在的 Broker 上保留的所有远程副本的 LEO 值,然后获取 Leader 副本的 HW 值。最后计算最新的 HW 值。计算逻辑为
currentHW = max(currentHW, min(LEO1, LEO2,...,LEOn)
了解了 Leader 副本的更新视角后,我们再从 Follower 副本的视角来看一下更新逻辑。
前面我们也了解到了 Follower 副本只干一件事,就是从 Leader 副本拉取消息。拉取后先把数据写入到本地,然后更新 LEO 值,最后更新 HW 值。这里更新 HW 值的步骤为:先获取 Leader 副本发送的 currentHW 值,再获取前面更新的 LEO 值,最后以两者之间较小的那个值作为 Follower 副本的 HW 值。
这样叙述可能还是有些抽象,所以我们通过一个例子再梳理一遍完整的更新流程。
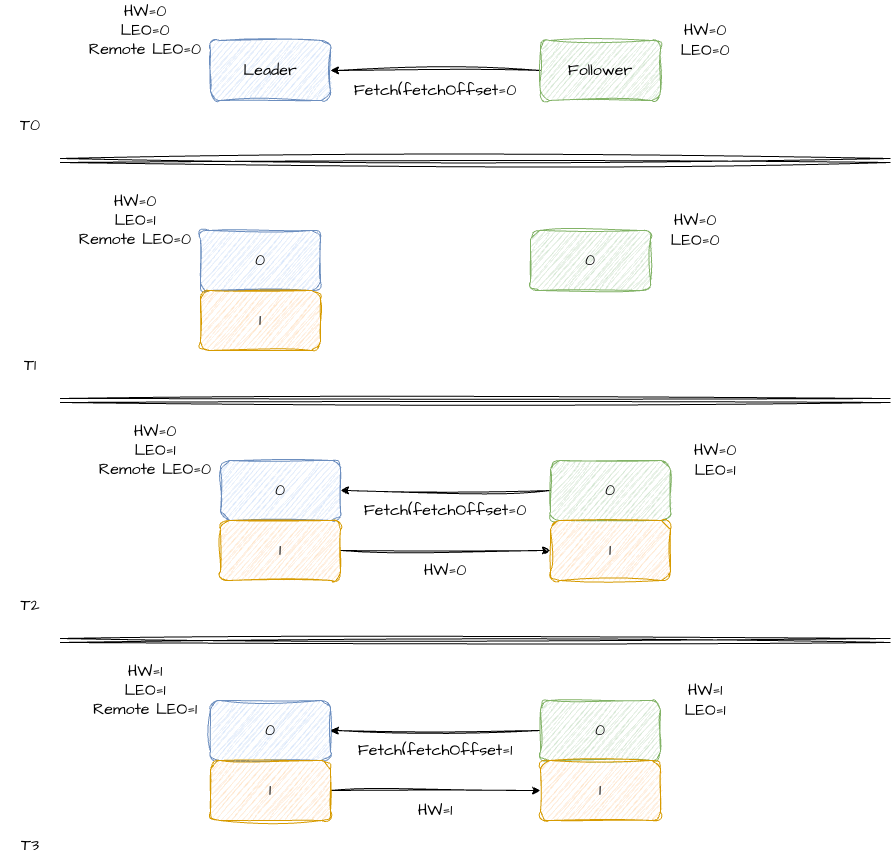
在这个例子中,我们有一个 Leader 副本和一个 Follower 副本。
在初始状态下(T0 时刻),Leader 副本的 HW、LEO、Remote LEO 都为 0,Follower 副本的 HW、LEO 也都是 0。
在 T1 时刻,Producer 向 Leader 写入一条消息,这时,Leader 副本的 LEO 值变为 1,其他值还是 0。
到 T2 时刻,Follower 副本向 Leader 副本发送了 Fetch 请求,拉取到 1 条消息,Follower 副本将自己的 LEO 值更新为 1。
到 T3 时刻,Follower 副本再次向 Leader 副本发送 Fetch 请求,请求中 fetchOffset = 1,Leader 副本收到请求后,将 Remote LEO 更新为 1,然后将 HW 更新为 1,在响应中,把 HW = 1 发给了 Follower 副本。Follower 副本收到响应后,会将自己的 HW 更新为 1。
至此,一次完整的副本同步流程就结束了。
位移主题
在了解完了 HW 和 LEO 这两个特殊的 Offset 之后,我们再来看一下 Kafka 是如何管理 Offset 的。
在旧版本的 Kafka 中,位移是保存在 ZooKeeper 中的,但是 ZooKeeper 的写入性能无法支撑高频的位移更新,因此 Kafka 决定将位移保存在一个内部的 Topic 中,这个 Topic 就是位移主题,它的名字是 __consumer_offsets,它默认有 50 个分区。
位移主题内部存储的数据就是一个键值对,其中 Key 保存了 GroupID + Topic Name + Partition Number 三元组,这保证了同一个消费组消费同一个分区的位移始终有相同的 Key。Value 中除了 Offset 之外,还保存了一些元信息以及时间戳。
最后要说明的是,Kafka 为了防止不断提交位移导致位移主题存储无限膨胀,默认对位移主题使用了日志压缩机制,对于同一个 Key 只会保留最新的一条数据。
总结
最后总结一下,本文我们一起了解了什么是 Offset,接着又学习了 HW 和 LEO 两个概念以及完整的副本同步流程。最后我们又学习了位移主题的相关概念。