从零学习Kafka:数据存储
不知道有没有朋友和我一样,虽然了解 Kafka 的逻辑存储,例如 Broker、Topic、Partition 这些概念,但是对于底层数据是如何存储还是比较模糊。这样聊起来 Kafka 数据存储时总有种一知半解的感觉。今天我们就一起来看一下 Kafka 底层数据到底是怎么存储的。
环境准备
在开始之前,我们先搭建好单机的 Kafka 集群,并且实际写入一批数据,这样就可以直接观察写入 Kafka 的数据了。下面可以跟着我的步骤一起搭建集群并写入数据。开始之前先说明一下,操作过程中可能涉及到一些配置参数的修改和检查,如果对配置参数不熟悉的话,可以查看上一篇文章。
首先到 Kafka 的下载页面下载最新版本的压缩包。
1 | https://www.apache.org/dyn/closer.cgi?path=/kafka/4.1.1/kafka_2.13-4.1.1.tgz |
下载好之后,进行解压并进入到对应的目录。
1 | tar -xzf kafka_2.13-4.1.1.tgz |
接着我们执行下面两条命令进行一些必要的配置。
1 | KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)" |
为了方便观察文件切分,我把 segment 文件大小调整为了 1MB,具体修改方法为编辑 config/server.properties 文件,修改 log.segment.bytes 参数的数值。

修改好之后,就可以启动 Kafka 集群了。
1 | bin/kafka-server-start.sh config/server.properties |
可以观察日志,看集群是否启动成功
集群启动之后,我们手动创建一个测试 topic。
1 | bin/kafka-topics.sh --create \ |
接着可以使用 Kafka 提供的压测工具来写入一批数据。
1 | bin/kafka-producer-perf-test.sh \ |
这里我分两次写入,每次写入了 50000 条数据,每条数据大小 100 字节,也就是一共写入了大约 10MB 数据。
现在把目光投向 /tmp/kraft-combined-logs 这个目录。如果没有这个目录,需要看一下集群配置的目录。
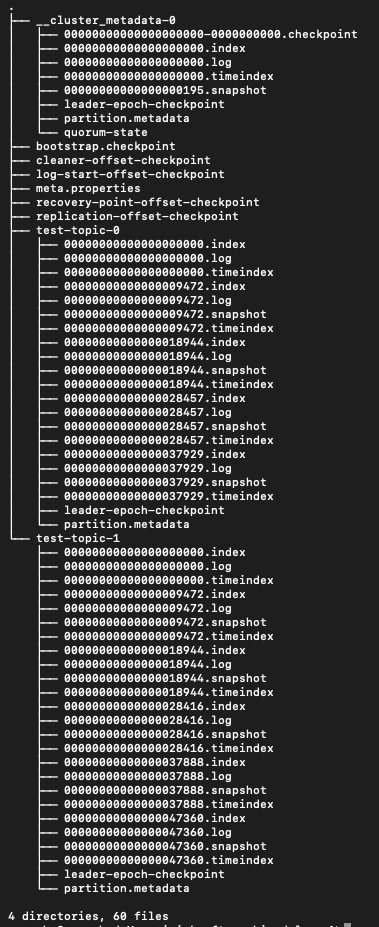
Broker 根目录
首先来看第一级目录
1 | drwxr-xr-x 10 wheel 320 1月 31 00:25 __cluster_metadata-0 |
这里一共有 9 个文件(目录),大体上可以分为三类:集群元数据、数据目录和 Checkpoint 文件。
集群元数据
meta.properties 是 Broker 的身份证,这里记录了 Cluster ID 和 Node ID。
bootstrap.checkpoint 用于记录集群初始化信息。
__cluster_metadata-0 是一个特殊的数据目录,它记录了集群的元数据,因此我将其归类到集群元数据中。
数据目录
test-topic-0 和 test-topic-1 这两个目录就是我们 test-topic 的两个 partition 存储数据的目录,待会儿再详细分析目录下的内容,现在你只需要知道 Kafka 是以 topic名 + partitionId 来命名数据目录的。
Checkpoint 文件
剩下的都是 checkpoint 文件,是用于宕机重启后的快速恢复的。
cleaner-offset-checkpoint 这是清理检查点文件,只有设置了 cleanup.policy=compact 时才有用,它记录了上一次 Log Compact 各个 partition 已清理的偏移量。
log-start-offset-checkpoint 日志起始位置,记录每个分区第一个有效的 Offset。
recovery-point-offset-checkpoint 记录每个 partition 已刷盘的 Offset。
replication-offset-checkpoint 记录每个 partition 已同步的 Offset,这里记录的就是 High Watermark。
Partition 存储结构
现在我们再来看下数据目录下的各个文件的作用是什么。
核心三兄弟
首先来介绍数据存储的核心,分别是 .log 、.index 和 .timeindex 文件,每个 Segment 都会有这三个文件,它们的文件名都是文件内存的第一条消息的 Offset。
log 文件
.log 是消息数据文件,Kafka 接收的消息都会顺序写入到这个文件中。可以通过下面这个命令查看文件的内容:
1 | ~/workspace/kafka_2.13-4.1.1/bin/kafka-dump-log.sh --files test-topic-0/00000000000000009472.log --print-data-log |
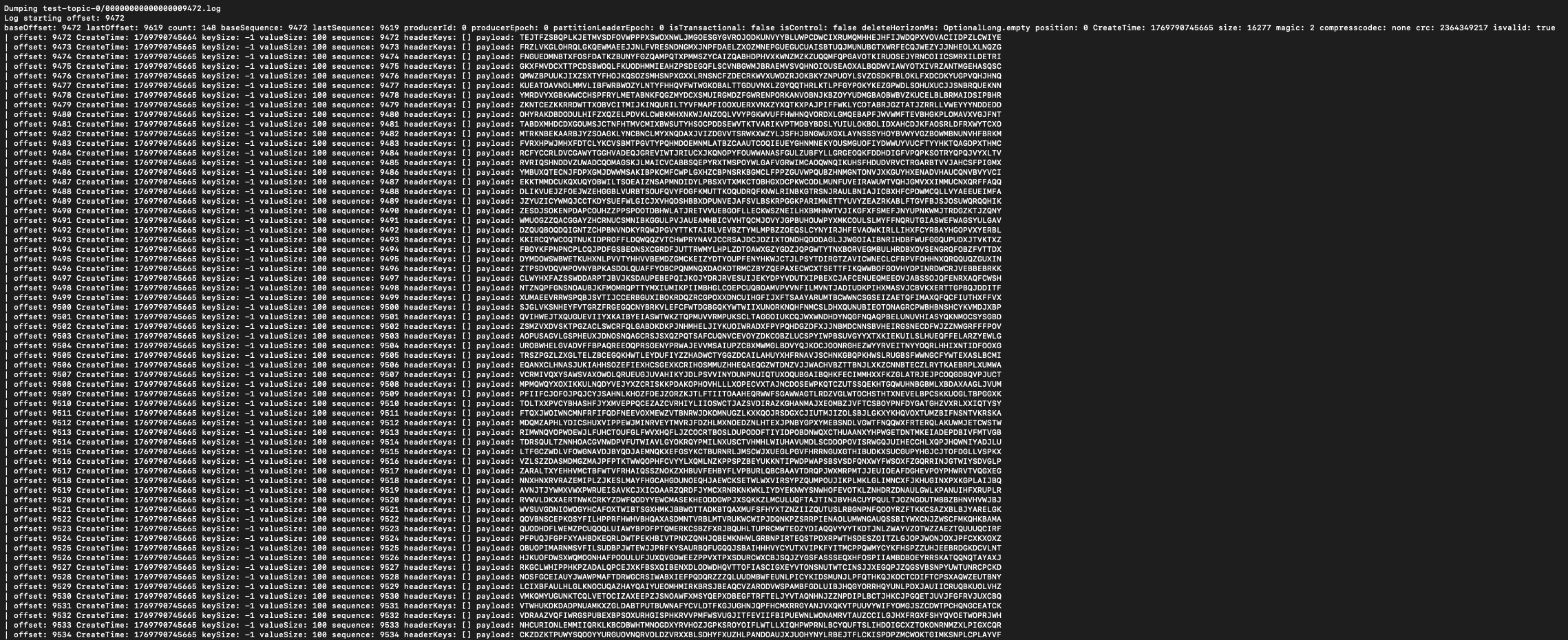
可以看到 log 文件中存储的主要是 Offset 和具体的序列化后的数据。
index 文件
.index 文件是偏移量索引文件,这里的索引是稀疏索引,文件内存储的是 Offset 到 log 文件位置的映射。我们使用下面这条命令来查看文件内容:
1 | ~/workspace/kafka_2.13-4.1.1/bin/kafka-dump-log.sh --files test-topic-0/00000000000000009472.index --deep-iteration |
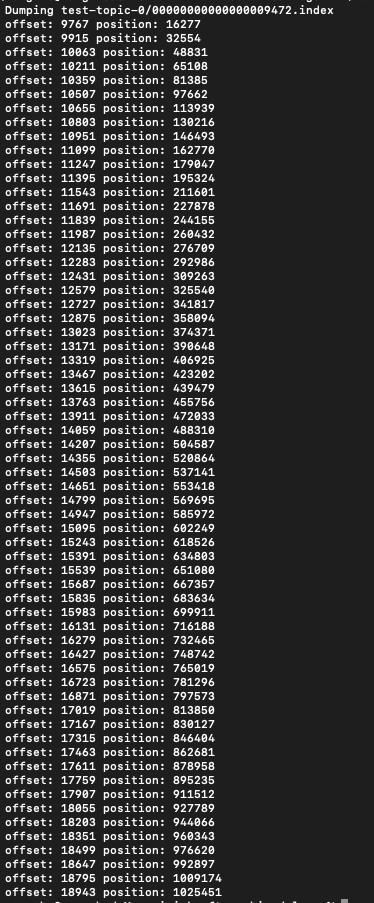
Kafka 默认每 4KB 数据写入一次索引,这个值可以通过 log.index.interval.bytes 参数调整。
timeindex 文件
.timeindex 是时间戳索引文件,用来支持 by_duration 按照时间回溯。查看文件内容的方法与查看 index 文件的方法类似:
1 | ~/workspace/kafka_2.13-4.1.1/bin/kafka-dump-log.sh --files test-topic-0/00000000000000009472.timeindex --deep-iteration |
我们在定位数据时,可以通过二分法在 index 索引文件中找到对应的数据位置(或者最接近的位置),也可以先通过时间在 timeindex 文件中找到最接近的 Offset,再到 index 文件中找到数据位置。
辅助文件
除了上述三个核心文件之外,在数据目录中还有三种辅助文件,我们来看下它们的作用。
.snapshot文件是用来记录事务快照的。用于 Exactly-Once 语义,如果 Broker 宕机,可以通过加载这个文件知道 Producer 之前发送到哪里了,防止数据重复。查看文件内容的方法如下
1 | ~/workspace/kafka_2.13-4.1.1/bin/kafka-dump-log.sh --files test-topic-0/00000000000000009472.snapshot |
leader-epoch-checkpoint文件是一个 Leader “任期表”,它记录了每一任 Leader 开始工作时的 Offset,主要用于在选主时保证数据一致性。partition.metadata文件是 Partition 的“身份证“,它存储了 Topic ID。
Page Cache
至此,我们已经比较细致的了解了 Kafka 底层存储结构。到这里不知道你会不会有疑问,Kafka 是写磁盘的,为什么速度还会这么快?
Kafka 在操作磁盘时,重度依赖操作系统的 Page Cache 功能,这个功能就是 Kafka 性能高的原因之一。简单来说,Page Cache 就是在读取磁盘时,操作系统会把读到的数据放到内存中一份,这块内存就是 Page Cache。在 Kafka 的应用场景中,Producer 写入顺序写入数据时,操作系统会先把数据写到 Page Cache,然后异步刷盘。在 Consumer 消费数据时,由于大部分情况下都是消费最新数据,因此要读的数据大概率还在 Page Cache 中, 操作系统可以直接从内存中返回。
题外话:Kafka 为什么不自己维护一套缓存机制呢?
我觉得主要有以下原因:
避免 GC 开销,如果自己在 JVM 内存中维护缓存,那么会带来很大的 GC 压力。如果用操作系统的 Page Cache,就完全不用担心 GC 问题。
Page Cache 对内存的利用率更高,如果 Kafka 进程重启,Page Cache 也还会在内存中,数据不需要重新加载。
逻辑简单,Kafka 只需要负责读写操作,剩下的缓存维护逻辑全部交给操作系统。
总结
本文我们了解了 Kafka 物理层面的数据存储。在 Broker 根目录下,有集群元数据、数据目录、Checkpoint 文件三种类型的文件(目录)。在数据目录中,最核心的三种文件是 .log、.index 和 .timeindex 三种文件,它们分别存储了数据、稀疏 Offset 索引以及时间戳与 Offset 的映射。
希望你通过阅读本文,可以对 Kafka 的数据存储有一个更加清晰的认识。