public List<KafkaPartitionSplit> snapshotState(long checkpointId) { List<KafkaPartitionSplit> splits = super.snapshotState(checkpointId); if (!commitOffsetsOnCheckpoint) { return splits; }
if (splits.isEmpty() && offsetsOfFinishedSplits.isEmpty()) { offsetsToCommit.put(checkpointId, Collections.emptyMap()); } else { Map<TopicPartition, OffsetAndMetadata> offsetsMap = offsetsToCommit.computeIfAbsent(checkpointId, id -> newHashMap<>()); // Put the offsets of the active splits. for (KafkaPartitionSplit split : splits) { // If the checkpoint is triggered before the partition starting offsets // is retrieved, do not commit the offsets for those partitions. if (split.getStartingOffset() >= 0) { offsetsMap.put( split.getTopicPartition(), newOffsetAndMetadata(split.getStartingOffset())); } } // Put offsets of all the finished splits. offsetsMap.putAll(offsetsOfFinishedSplits); } return splits; }
public RecordsWithSplitIds<ConsumerRecord<byte[], byte[]>> fetch() throws IOException { ConsumerRecords<byte[], byte[]> consumerRecords; try { consumerRecords = consumer.poll(Duration.ofMillis(POLL_TIMEOUT)); } catch (WakeupException | IllegalStateException e) { // IllegalStateException will be thrown if the consumer is not assigned any partitions. // This happens if all assigned partitions are invalid or empty (starting offset >= // stopping offset). We just mark empty partitions as finished and return an empty // record container, and this consumer will be closed by SplitFetcherManager. KafkaPartitionSplitRecordsrecordsBySplits= newKafkaPartitionSplitRecords( ConsumerRecords.empty(), kafkaSourceReaderMetrics); markEmptySplitsAsFinished(recordsBySplits); return recordsBySplits; } KafkaPartitionSplitRecordsrecordsBySplits= newKafkaPartitionSplitRecords(consumerRecords, kafkaSourceReaderMetrics); List<TopicPartition> finishedPartitions = newArrayList<>(); for (TopicPartition tp : consumer.assignment()) { longstoppingOffset= getStoppingOffset(tp); longconsumerPosition= getConsumerPosition(tp, "retrieving consumer position"); // Stop fetching when the consumer's position reaches the stoppingOffset. // Control messages may follow the last record; therefore, using the last record's // offset as a stopping condition could result in indefinite blocking. if (consumerPosition >= stoppingOffset) { LOG.debug( "Position of {}: {}, has reached stopping offset: {}", tp, consumerPosition, stoppingOffset); recordsBySplits.setPartitionStoppingOffset(tp, stoppingOffset); finishSplitAtRecord( tp, stoppingOffset, consumerPosition, finishedPartitions, recordsBySplits); } }
// Only track non-empty partition's record lag if it never appears before consumerRecords .partitions() .forEach( trackTp -> { kafkaSourceReaderMetrics.maybeAddRecordsLagMetric(consumer, trackTp); });
markEmptySplitsAsFinished(recordsBySplits);
// Unassign the partitions that has finished. if (!finishedPartitions.isEmpty()) { finishedPartitions.forEach(kafkaSourceReaderMetrics::removeRecordsLagMetric); unassignPartitions(finishedPartitions); }
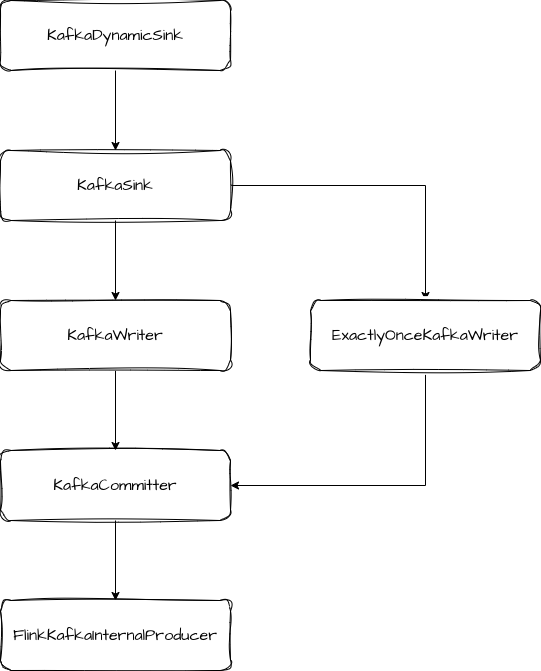
public Collection<KafkaCommittable> prepareCommit() { // only return a KafkaCommittable if the current transaction has been written some data if (currentProducer.hasRecordsInTransaction()) { KafkaCommittablecommittable= KafkaCommittable.of(currentProducer); LOG.debug("Prepare {}.", committable); currentProducer.precommitTransaction(); return Collections.singletonList(committable); }
// otherwise, we recycle the producer (the pool will reset the transaction state) producerPool.recycle(currentProducer); return Collections.emptyList(); }
public List<KafkaWriterState> snapshotState(long checkpointId)throws IOException { // recycle committed producers TransactionFinished finishedTransaction; while ((finishedTransaction = backchannel.poll()) != null) { producerPool.recycleByTransactionId( finishedTransaction.getTransactionId(), finishedTransaction.isSuccess()); } // persist the ongoing transactions into the state; these will not be aborted on restart Collection<CheckpointTransaction> ongoingTransactions = producerPool.getOngoingTransactions(); currentProducer = startTransaction(checkpointId + 1); return createSnapshots(ongoingTransactions); }
private List<KafkaWriterState> createSnapshots( Collection<CheckpointTransaction> ongoingTransactions) { List<KafkaWriterState> states = newArrayList<>(); int[] subtaskIds = this.ownedSubtaskIds; for (intindex=0; index < subtaskIds.length; index++) { intownedSubtask= subtaskIds[index]; states.add( newKafkaWriterState( transactionalIdPrefix, ownedSubtask, totalNumberOfOwnedSubtasks, transactionNamingStrategy.getOwnership(), // new transactions are only created with the first owned subtask id index == 0 ? ongoingTransactions : List.of())); } LOG.debug("Snapshotting state {}", states); return states; }