Flink源码阅读:集群启动
前文中,我们已经了解了 Flink 的三种执行图是怎么生成的。今天继续看一下 Flink 集群是如何启动的。
启动脚本
集群启动脚本的位置在:
1 | flink-dist/src/main/flink-bin/bin/start-cluster.sh |
脚本会负责启动 JobManager 和 TaskManager,我们主要关注 standalone 启动模式,具体的流程见下图。

从图中可以看出 JobManager 是通过 jobmanager.sh 文件启动的,TaskManager 是通过taskmanager.sh 启动的,两者都调用了 flink-daemon.sh,通过传递不同的参数,最终运行不同的 Java 类。
1 | case $DAEMON in |
JobManager 启动流程
在 StandaloneSessionClusterEntrypoint 的 main 方法中,主要就是加载各种配置和环境变量,然后调用 ClusterEntrypoint.runClusterEntrypoint 来启动集群。跟着调用链一直找到 ClusterEntrypoint.runCluster 方法,这里会启动 ResourceManager、DispatcherRunner 等组件。
1 | private void runCluster(Configuration configuration, PluginManager pluginManager) |
下面来详细看一下这几个方法, initializeServices 就是负责初始化各种服务,有几个比较重要的可以着重关注下:
1 | // 初始化并启动一个通用的 RPC Service |
createDispatcherResourceManagerComponentFactory 这个方法就是创建了三个工厂类,不需要过多介绍。我们重点关注 dispatcherResourceManagerComponentFactory.create 方法,即 ResourceManager、DispatcherRunner、WebMonitorEndpoint 是如何启动的。
WebMonitorEndpoint
WebMonitorEndpoint 的启动流程图如下,图中细箭头代表同一个方法中顺序调用,粗箭头代表进入上一个方法内部的调用。
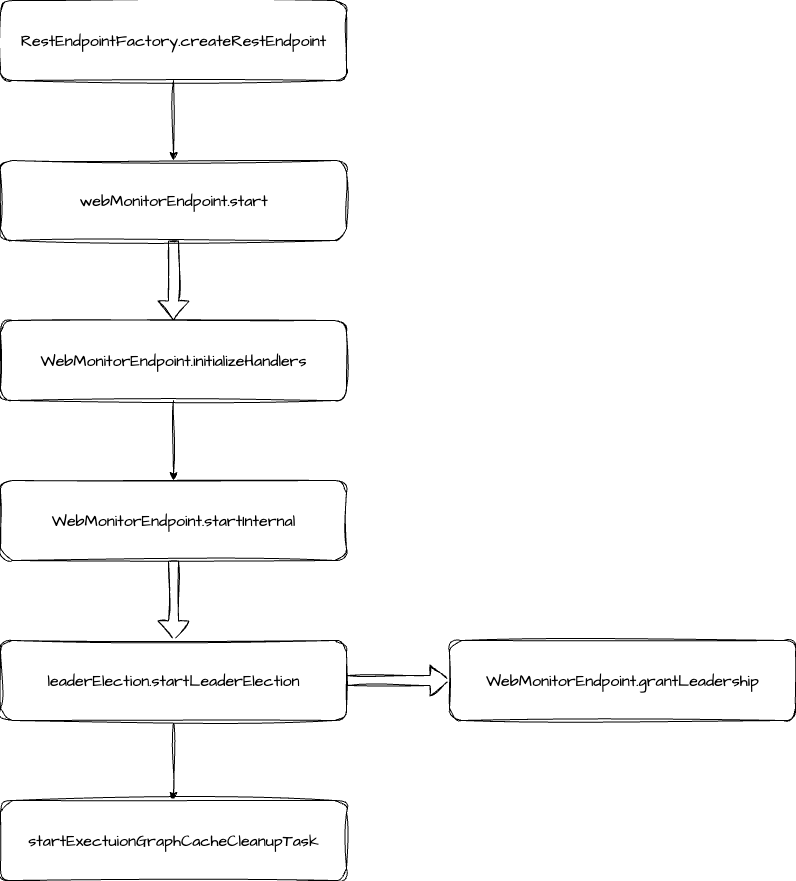
WebMonitorEndpoint 创建和启动步骤如下:
通过工厂创建出了 WebMonitorEndpoint,这里就是比较常规的初始化操作。
调用 WebMonitorEndpoint 的 start 方法开始启动,start 方法内部先是创建了一个 Router 并调用 initializeHandlers 创建了一大堆 handler(是真的一大堆,这个方法有接近一千行,都是在创建 handler),创建完成之后,对 handler 进行排序和去重,再把它们都注册到 Router 中。这里排序是为了确保路由匹配的正确性,排序规则是先静态路径(/jobs/overview),后动态路径(/jobs/:jobid),假如我们没有排序,先注册了 /jobs/:jobid ,后注册 /jobs/overview ,这时当我们请求 /jobs/overview 时,就会被错误的路由到 /jobs/:jobid 上去。
是调用 startInternal 方法,在 startInternal 方法内部只有 leader 选举和启动缓存清理任务两个步骤。
ResourceManager
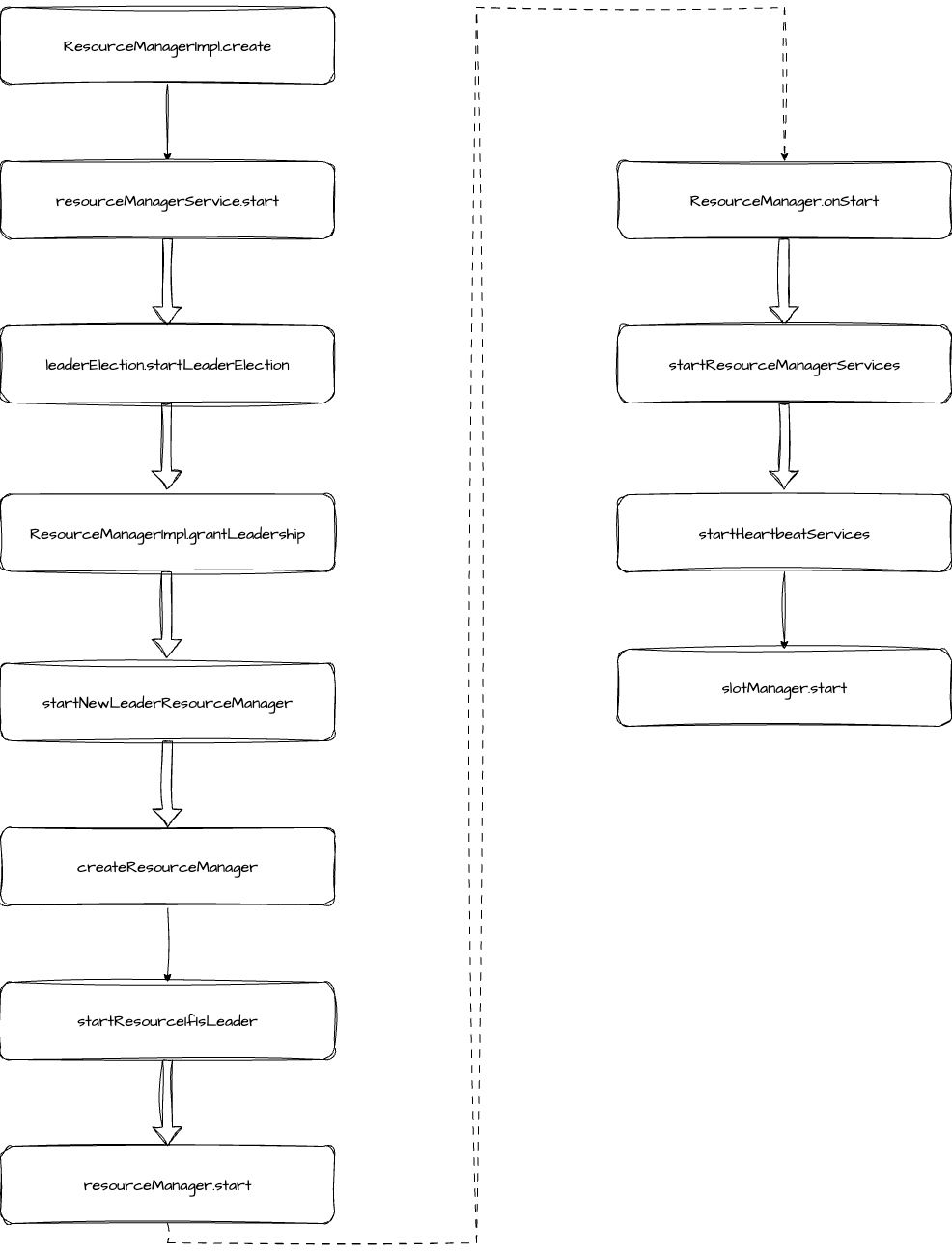
ResourceManager 创建和启动步骤如下:
调用 ResourceManagerServiceImpl.create 方法创建 ResourceManagerService,这里只是创建 ResourceManager 服务,实际创建 ResourceManager 在后面的步骤中。
调用 resourceManagerService.start 方法启动服务,这里就是启动选主服务,standalne 模式直接调用 grantLeadership 成为 leader。
成为 leader 后,就会调用 startNewLeaderResourceManager 方法,这个方法中会调用 resourceManagerFactory.createResourceManager 正式创建 resourceManager。创建完成后,就会调用 resourceManager.start 来启动它。
启动后会回调 ResourceManager.onStart 方法。这里调用 startHeartbeatServices 启动了两个心跳服务,一个是 ResourceManager 和 TaskManager 之间的心跳,一个是 ResourceManager 和 JobManager 之间的心跳,然后会启动 SlotManager。SlotManager 可以被当作 Flink 集群的资源调度中心。它会负责管理集群中的所有 Slot 资源,也需要响应 JobManager 的资源请求。
DispatcherRunner
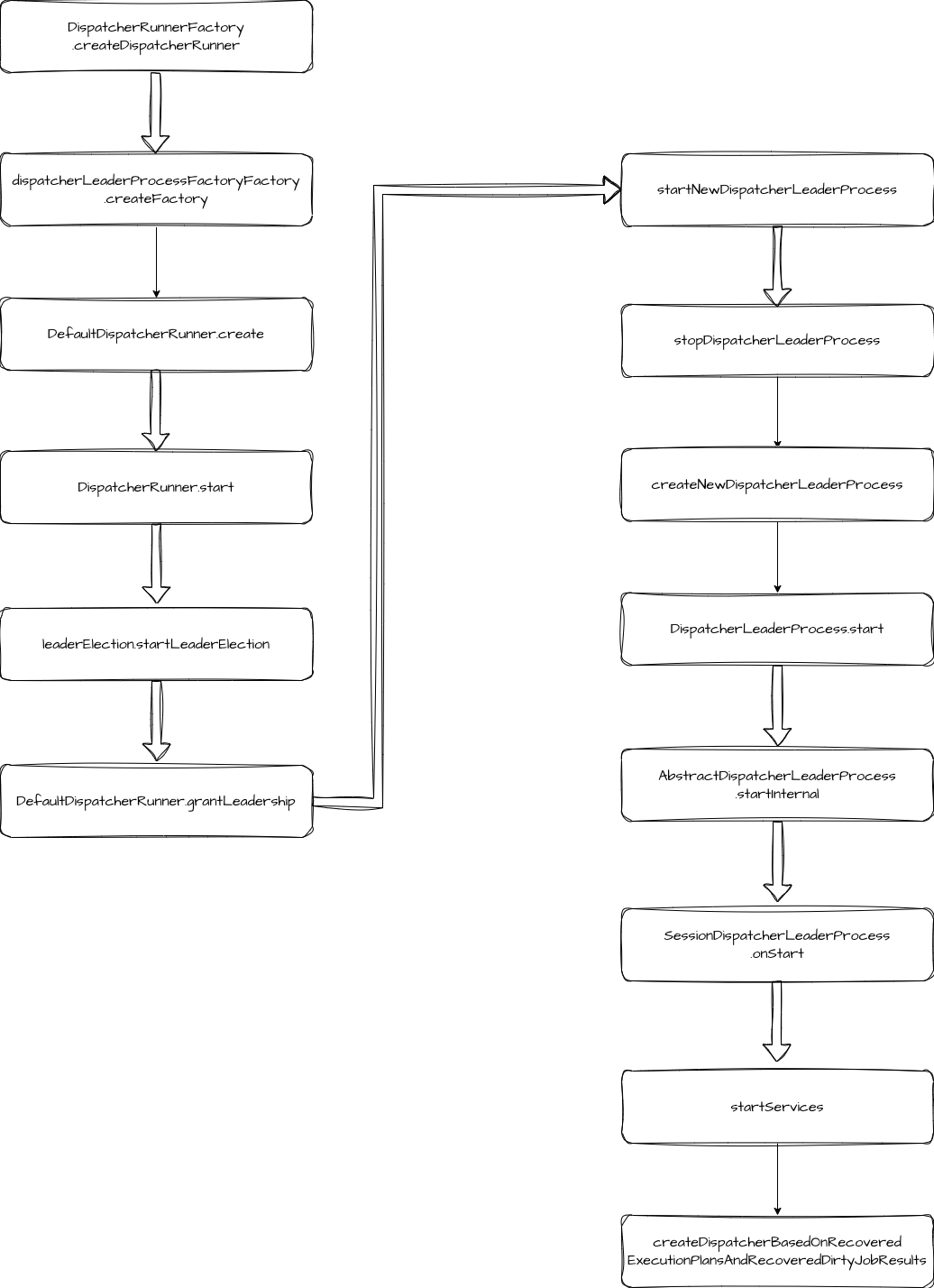
先创建工厂,创建完成后调用 DefaultDispatcherRunner.create 创建出 DispatcherRunner,接着是调用 start 启动选主流程。
选主完成后就调用 startNewDispatcherLeaderProcess 启动新的流程。启动新的流程需要先关闭旧流程,然后创建新的 dispatcherLeaderProcess,并调用 start 启动。
启动时,会回调 onStart 方法。
回调方法中,先启动 executionPlanStore,它主要是用于持久化 JobGraph。然后恢复执行计划,重建状态(如果是从失败中恢复),实例化 Dispatcher,完成作业启动。
TaskManager 启动流程
TaskManager 是 Flink 的执行节点,其最小执行单元是 slot。TaskManager 启动流程也主要是和资源管理相关,包括 slot 列表的管理和与 ResourceManager 的通信。
TaskManager 启动流程大体分为以下几部分:
构建并启动 TaskManagerRunner(蓝色部分)
启动 TaskExecutor(红色部分)
完成与 ResourceManager 的连接(橙色部分)
启动 TaskManagerRunner
在 TaskManagerRunner 的 start 方法中,有两个步骤:
第一步是调用 startTaskManagerRunnerServices 创建和启动了很多服务,这一点和 JobManager 的启动流程比较像。这些服务包括了高可用服务、心跳服务、监控指标服务等,这里也创建了 taskExecutorService,它的启动在第二步。
第二步是调用 taskExecutorService.start 方法,启动 TaskExecutorService,它内部主要负责启动 TaskExecutor。
启动 TaskExecutor
TaskExecutor 是 TaskManager 内部的一个核心组件,负责帮助 TaskManager 完成 task 的部署和执行等核心操作。
在上一步调用 taskExecutor 的 start 方法后,会回调 onStart 方法,这里主要是三个步骤
连接 ResourceManager 以及注册监听
启动 taskSlotTable
连接 JobMaster 以及注册监听
第一步我们在下面详细解释。第二步启动的 TaskSlotTable 是 TaskManager 中负责资源的核心组件,它维护了一个 Slot 列表,管理每个 Slot 的状态,负责 Slot 的分配和释放。第三步主要是和 JobMaster 建立连接并保持心跳,同时也会接收 Slot 申请的请求。
连接 ResourceManager
TaskExecutor 注册完监听之后,会收到 ResourceManagerLeaderListener.notifyLeaderAddress 方法回调。回调方法中,会创建一个 TaskExecutorToResourceManagerConnection 实例并启动它。这个类是用来将 TaskExecutor 注册到 ResourceManager,注册成功会回调 onRegistrationSuccess 方法。回调成功的方法中,TaskManager 会调用 resourceManagerGateway.sendSlotReport 将 Slot 的状态进行上报。
总结
本文介绍了 Flink 集群在 Standalone 模式下的启动过程,其中 JobManager 重点介绍了 WebMonitorEndpoint、ResourceManager 和 DispatcherRunner 这三个组件的启动过程。TaskManager 主要介绍了启动 TaskExecutor 和连接 ResourceManager 的过程。