Flink学习笔记:状态后端
我们继续来聊 Flink 容错相关的内容。前面在介绍 Checkpoint 和 Savepoint 时提到了 State 的稳定存储,那究竟如何存储以及存储在什么地方呢?相信通过读完本文之后,你会有答案。
State Backend 分类
在 Flink 中状态后端(State Backend)是用来管理状态如何存储的。当前内置了两种 State Backend,分别是 HashMapStateBackend 和 EmbeddedRocksDBStateBackend。Flink 默认使用的是 HashMapStateBackend。
HashMapStateBackend
在 HashMapBackend 中,数据是以 Java 对象的形式存储的,它适用于有较大 State,较长 window 和 较大 key/value 状态的场景。同时适用于高可用场景。在使用 HashMapStateBackend 时,建议把 managed memory 设置为 0,以此来增加用户代码可使用的内存。
EmbeddedRocksDBStateBackend
对于 EmbeddedRocksDBStateBackend 而言,数据是存储在 RocksDB 中的,在存储之前,要对数据进行序列化。EmbeddedRocksDBStateBackend 也存在一定局限性,那就是最大只能支持每个 key/value 存储 2^31 字节大小的数据,这是当前 RocksDB JNI 的限制。
EmbeddedRocksDBStateBackend 也有一定的优势,其一是它是目前唯一支持增量 Checkpoint 的 State Backend。其二是因为它是外部存储,因此它可以支持非常大的 State,非常长的窗口。
增量快照只包含自上一次快照完成后被修改的记录,所以增量快照的一大优点就是可以显著减少快照的耗时。在恢复时间上,要分情况讨论,如果瓶颈在网络带宽,那么增量快照的恢复时间要比全量快照更长,因为增量快照包含的多个 sst 文件之间可能存在重复数据。如果瓶颈在 CPU 或 IO,那增量快照恢复时间更短,因为增量快照不需要恢复不需要解析 Flink 统一的存储格式来重建本地的 RocksDB 表,而是直接基于 sst 文件加载。
Checkpoint 存储类型
了解了 State Backend 分类之后,我们再来看 Checkpoint 的存储类型。它也分为两类:JobManagerCheckpointStorage 和 FileSystemCheckpointStorage。
JobManagerCheckpointStorage
JobManagerCheckpointStorage 是将快照存储在 JobManager 的堆内存中。JobManagerCheckpointStorage 在使用时有一定限制:
默认每个 State 大小最大为 5MB
总的状态大小不能超过 JobManager 内存
基于这些限制,JobManagerCheckpointStorage 只适用于本地的开发和调试。
FileSystemCheckpointStorage
FileSystemCheckpointStorage 是将状态数据保存在外部存储中,要适用 FileSystemCheckpointStorage,需要配置文件系统的 URL。例如:“hdfs://namenode:40010/flink/checkpoints”。而元数据则存储在 JobManager 的内存中。
Checkpoint 存储设置
有了前面 State Backend 和 存储类型的分类之后,我们就可以将其进行组合,得到最终 Checkpoint 的存储了。
目前共有三种组合,也对应了旧版本的三种 State Backend。
MemoryStateBackend
MemoryStateBackend 对应了 HashMapStateBackend 和 JobManagerCheckpointStorage 的组合。
设置方法为
1 | state.backend: hashmap |
或
1 | Configuration config = new Configuration(); |
FsStateBackend
FsStateBackend 对应了 HashMapStateBackend 和 FileSystemCheckpointStorage 的组合。
它的设置方法为:
1 | state.backend: hashmap |
或
1 | Configuration config = new Configuration(); |
RocksDBStateBackend
RocksDBStateBackend 对应了 EmbeddedRocksDBStateBackend 和 FileSystemCheckpointStorage 的组合。
它的设置方法为
1 | state.backend: rocksdb |
或
1 | Configuration config = new Configuration(); |
State 序列化与反序列化
我们前面在创建 State 的描述符时,指定了 State 的类型,这其实就是告诉 Flink 应该如何去序列化我们的 State。当然,也可以自定义 State 序列化器,自定义序列化器需要 TypeSerializer,然后在创建描述符时指定。
1 | public class CustomTypeSerializer extends TypeSerializer<Tuple2<String, Integer>> {...}; |
Flink 中状态分为两种类型,一种是基于 Heap,一种是不基于 Heap。
Heap state backends
首先看基于 Heap 的,HashMapStateBackend 是基于 Heap 的。
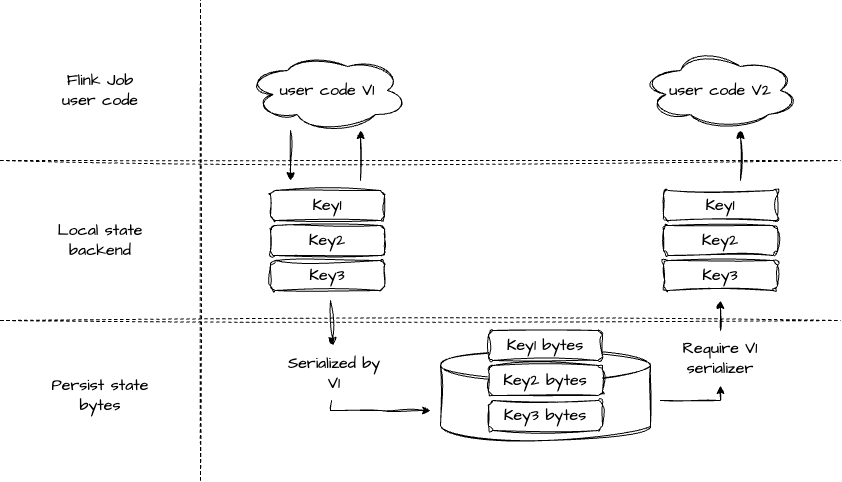
Heap state backend 存在本地的状态后端中的是非序列化的数据,当触发 Checkpoint / Savepoint 时,会用指定的序列化器将数据序列化,然后存储到指定的稳定存储中。
如果我们对程序进行了升级,这时要从 State 恢复的话,需要先将稳定存储中的数据进行反序列化,然后将结果加载到 TM 的内存中,供 user code 使用。
Off-heap state backends
EmbeddedRocksDBStateBackend 就是一种不基于 Heap 的状态。
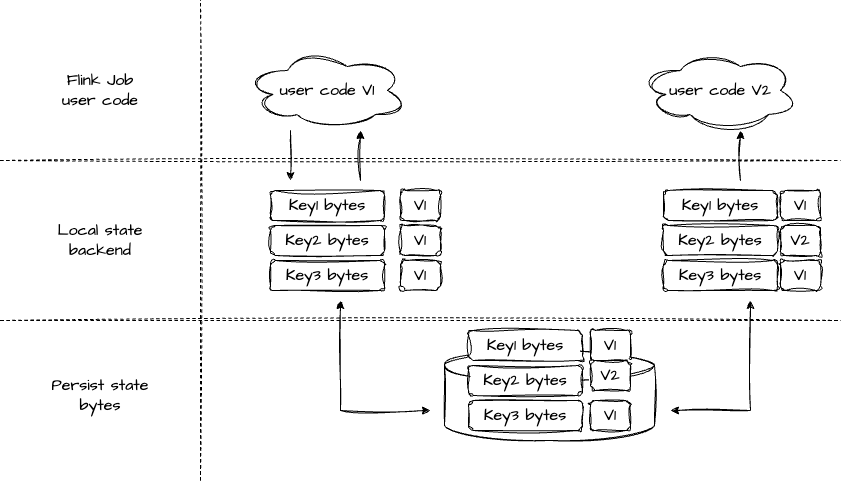
不基于 Heap 的状态在写入本地 State 时就会进行序列化,序列化后的数据会写入到堆外内存。在触发 Checkpoint 时,就只是把数据文件转存到稳定存储中。
当我们的任务完成升级后,会先将二进制文件恢复到 TM 的内存中,这里是一个文件加载的过程。当我们要使用 State 时,才会进行反序列化,注意这里只会对使用到的 State 进行反序列化读取以及后续的更新,没有使用到的还是保持旧版本的数据。
总结
本文我们重点介绍了状态后端的存储。State Backend 分为 HashMapStateBackend 和 EmbeddedRocksDBStateBackend,其存储类型又分为 JobManagerCheckpointStorage 和 FileSystemCheckpointStorage。最终我们会有三种不同的状态后端:MemoryStateBackend、FsStateBackend 和 RocksDBStateBackend。最后我们还介绍了 State 的两种不同的序列化。
相信通过本文的介绍,你已经可以回答开篇的问题了。