Flink学习笔记:如何做容错
现在我们已经了解了 Flink 的状态如何定义和使用,那 Flink 是如何做容错的呢?今天我们一起来了解一下。
先来回答问题, Flink 是通过状态快照来做容错的,在 Flink 中状态快照分为 Checkpoint 和 Savepoint 两种。
Checkpoint
Checkpoint 是一种自动执行的快照,其目的是让 Flink 任务可以从故障中恢复。它可以是增量的,并且为快速恢复进行了优化。
如何开启 Checkpoint
Checkpoint 默认是关闭的,开启的方法很简单,只需要调用 enableCheckpointing() 方法即可。除了这个方法之外,Checkpoint 还有一些高级特性。我们来看几个比较常用的,更多的选项可以查看官方文档。
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
CheckpointingMode:支持 EXACTLY_ONCE 和 AT_LEAST_ONCE 两种,精确一次有更好的数据一致性,而至少一次可以提供更低的延迟。
MinPauseBetweenCheckpoints:Checkpoint 之间最小间隔时间,单位是毫秒,即前一次 Checkpoint 执行完成之后必须间隔 n 毫秒之后才会开启下一次 Checkpoint。
CheckpointTimeout:Checkpoint 超时时间,单位为毫秒,表示 Checkpoint 必须在 n 毫秒内完成,否则就会因超时失败。
TolerableCheckpointFailureNumber:可容忍连续失败次数,默认是0。超过这个阈值之后,整个 Flink 作业会触发 fail over。
MaxConcurrentCheckpoints:Checkpoint 并发数,默认情况下是1,在同一时间只允许一个 Checkpoint 执行。这个参数不能和最小间隔时间一起使用。
ExternalizedCheckpointRetention:周期存储 Checkpoint 到外部存储,这样在任务失败时 Checkpoint 也不会被删除。
enableUnalignedCheckpoints:使用非对齐的 Checkpoint,可以减少在产生背压时 Checkpoint 的创建时间。
Checkpoint 存储
Flink 提供了两种存储类型:JobManagerCheckpointStorage 和 FileSystemCheckpointStorage。默认是 JobManagerCheckpointStorage,即将 Checkpoint 快照存储在 JobManager 的堆内存中,也可以设置 Checkpoint 目录,将快照存储在外部存储系统中。
Checkpoint 目录通过 execution.checkpointing.dir 设置项设置。其目录结构如下:
1 | /user-defined-checkpoint-dir |
Checkpoint 工作原理
在前文中,我们曾经提到过 Checkpoint Coordinator,它是 JobManager 的其中一个模块。它在 Checkpoint 过程中担任着重要的角色。
现在来看下 Checkpoint 的完整流程
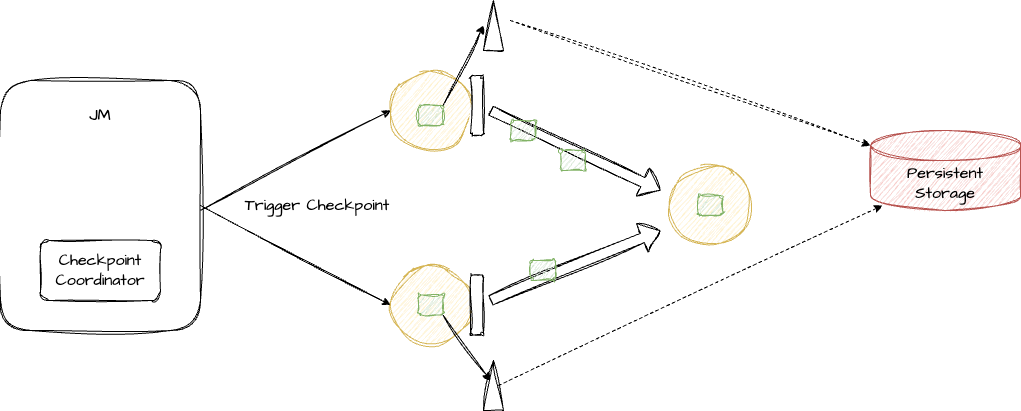
1、Checkpoint Coordinator 触发所有 Source 节点开始 Checkpoint,Source 收到触发命令后,会将自己的 State 进行持久化(图中三角形),并且向下游发送 barrier 事件(图中的小矩形)。当 Source 节点的 State 持久化完成之后,会数据存储的地址发送给 Checkpoint Coordinator。
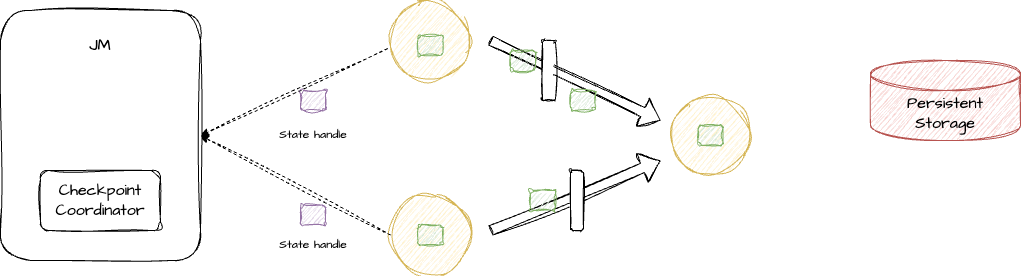
2、barrier 事件随着事件流传输到下游节点,当下游节点收到所有的上游 barrier 事件后,也会将自己的 State 持久化,并继续向下传播 barrier 事件。持久化完成后,也同样将数据存储地址发送给 Checkpoint Coordinator。
3、当所有的算子都完成持久化过程后,Checkpoint Coordinator 会将一些元数据进行持久化。
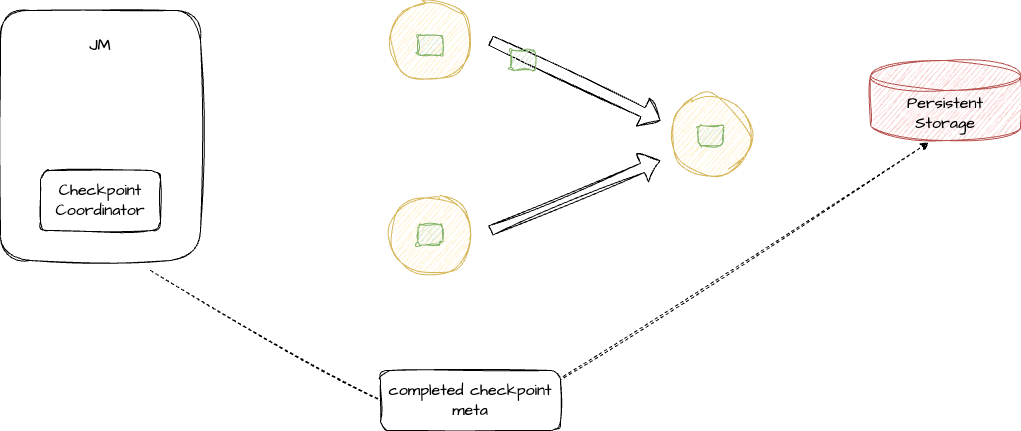
至此,一次完整的 Checkpoint 流程就结束了。
Savepoint
学习完 Checkpoint 之后,我们再来了解下另一种快照——Savepoint。
Savepoint 是依据 checkpoint 机制创建的一致性镜像。通常用来做 Flink 作业的重启或更新等运维操作。Savepoint 包含稳定存储上的二进制文件(作业状态的镜像)和元数据文件两部分。
使用 Savepoint
根据官方文档的提示,在我们的程序中,最好显式调用 uid() 方法来为算子指定一个 ID,这些 ID 被用来恢复每个算子的状态。如果不指定的话,Flink 任务会自动生成算子 ID,但是生成的 ID 与程序结构有关,也就是说,如果程序的结构改变了的话,就没有办法从 Savepoint 恢复对应算子的状态了。
有了这个前提条件之后,我们就可以使用命令来操作 Savepoint 了。
1 | // 触发 savepoint |
在 触发 savepoint 时,我们可以指定格式,两种格式的区别是:
canonical(标准格式):在任何存储都保持统一格式,重在保证兼容性。
native(原生格式):标准格式创建和恢复都很慢,原生格式是以特定的状态后端的格式生成,可以更快的创建和恢复。
Checkpoint 与 Savepoint 区别
这是面试最常见的问题之一,有了 checkpoint,为什么还需要 savepoint?或者说两者之间有什么区别?
从概念上来讲,Checkpoint 类似数据库的恢复日志,而 Savepoint 类似数据库的备份。Checkpoint 主要用于作业故障的恢复,它的管理和删除也都是 Flink 内部处理,用户不需要过多关注。Savepoint 主要用于有计划的手动运维,例如升级 Flink 版本。它的创建、删除操作都需要用户手动执行。
下面是官方文档给出的 Checkpoint 和 Savepoint 支持的操作。✓表示完全支持,x表示不支持,!表示目前有效,但没有正式保证支持,使用时存在一定风险。
| 操作 | 标准 Savepoint | 原生 Savepoint | 对齐 Checkpoint | 非对齐 Checkpoint |
|---|---|---|---|---|
| 更换状态后端 | ✓ | x | x | x |
| State Processor API (写) | ✓ | x | x | x |
| State Processor API (读) | ✓ | ! | ! | x |
| 自包含和可移动 | ✓ | ✓ | x | x |
| Schema 变更 | ✓ | ! | ! | ! |
| 任意 job 升级 | ✓ | ✓ | ✓ | x |
| 非任意 job 升级 | ✓ | ✓ | ✓ | ✓ |
| Flink 小版本升级 | ✓ | ✓ | ✓ | x |
| Flink bug/patch 版本升级 | ✓ | ✓ | ✓ | ✓ |
| 扩缩容 | ✓ | ✓ | ✓ | ✓ |
总结
本文我们介绍了 Flink 是如何做容错的,分别介绍了 Checkpoint 和 Savepoint,以及它们之间的区别。本文多次提到了 Checkpoint 和 Savepoint 依赖的稳定存储,我会在下一篇文章进行详细的介绍。