Flink学习笔记:状态类型和应用
Flink 被广泛应用的原因,除了我们前面提到的对时间以及窗口的应用之外,另一点就是它强大的容错机制,以及对 Exactly Once 的支持。
今天就来了解一下 Flink 的状态以及应用,首先第一个问题是:什么是有状态计算?
基本概念
在数据流处理中,大部分操作都是每次只处理一个事件,比如对输入的数据进行结构化解析,这类操作我们称为无状态计算。而有些操作则需要记住多个事件并进行处理,比如前面我们在窗口中对数据做的求和操作,这类操作我们称之为有状态计算。
在 Flink 中,状态的另一个重要作用是用来做故障恢复,故障恢复主要依赖于 checkpoint 和 savepoint。当我们使用状态时,通常需要从 State Backend 读取。
通过介绍有状态计算的基本概念,我们又引出了 checkpoint、State Backend 等概念,下面我们再来一一解释。
状态分类
Flink 状态分类可以参考下图
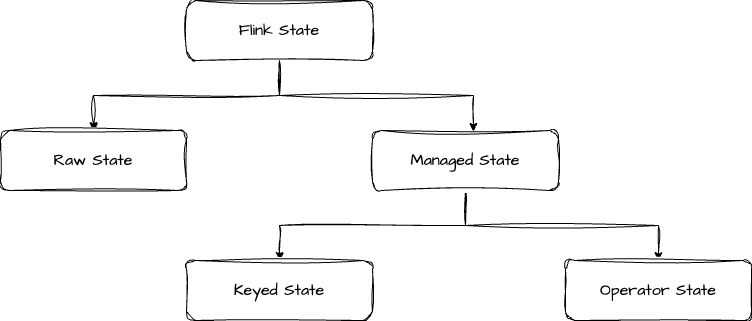
首先是分为 Raw State 和 Managed State 两大类,我们分别从管理方式、数据类型、适用场景这三个方面来看它们的区别
| Raw State | Managed State | |
|---|---|---|
| 管理方式 | 开发者自行管理,需要手动序列化和反序列化 | 由 Flink Runtime 管理,自动存储和恢复数据 |
| 数据类型 | 仅支持 byte 数组 | 支持 value, list, map |
| 适用场景 | 需要自定义 Operator | 支持大部分计算场景 |
Managed State 又分为 Keyed State 和 Operator State 两类,下面我们详细介绍这两类状态。
Keyed State
Keyed State 只能用在 KeyedStream 上,也就是在使用前,要先对数据流进行 keyBy 操作。Keyed State 支持以下几种状态类型:
ValueState
:保存一个值,可以通过 update() 方法更新,通过 value() 方法获取保存的值。 ListState
:保存一个 list,可以通过 add() 或 addAll() 方法向 list 中添加元素,也可以通过 update() 直接覆盖。使用 get() 方法获取整个列表。 ReducingState
:保存一个值,表示添加到状态所有值的聚合,使用 add() 方法添加元素,使用 get() 方法获取保存的值。 AggregatingState<IN, OUT>:保存一个值,与 ReducingState 不同的是,输入和输出的元素类型可以不同。
MapState<UK, UV>:保存一个 map,可以使用 put() 或 putAll() 添加键值对,使用 get() 获取值。
在知道了各个类型的 Keyed State 怎么用之后,我们再来看如何创建一个 Keyed State。以 ValueState 为例。
1 | ValueStateDescriptor<Tuple2<Long, Long>> descriptor = |
要想创建一个 State,必须先创建一个 StateDescriptor,然后通过 RuntimeContext 来获取 State。每个 State 都对应一种 StateDescriptor。
1 | ValueState<T> getState(ValueStateDescriptor<T>) |
Operator State
算子状态也称为非 keyed 状态,是绑定到一个并行算子实例的状态。State 需要支持重新分布。 最典型的是 Kafka Connector 中,维护了一个 topic partitions 和 offset 的 map 作为一个算子状态。
和 Keyed State 类似,想要创建一个 Operator State,同样也需要一个 StateDescriptor,同时,需要实现 CheckpointedFunction,它提供了两个方法,分别是在 checkpoint 时 调用的 snapshotState() 和 自定义函数初始化时调用的 initializeState()。
Talk is cheap, show me your code!
我们来看 Flink 官方文档提供的 Demo
1 | public class BufferingSink |
在这个例子中,我们在 initializeState 方法中使用 getOperatorStateStore().getListState() 创建了一个 ListState,然后将数据缓存到这个 list 中,当缓存数据大小超过一个阈值时,再统一发送到下游。
这里还有一个方法值得注意,就是 isRestored(),它是用来判断当前任务是否是从故障中恢复的,如果是,我们需要执行故障恢复相关的逻辑。在这个例子中就是把 state 的数据恢复到本地的变量中。
Broadcast State
了解了如何创建和使用 Operator State 之后,我们再来看一种特殊的 Operator State —— Broadcast State。
Broadcast State 本身是类似于 Map 类型的格式,使用时需要指定 key 和 value 的类型。它的作用是将一条数据流的数据广播到下游算子的各个节点。
Broadcast State 的一个比较常见的作用就是大流关联小流。例如,我们有一个订单流,需要关联商品详情,这时可以把商品详情的流作为 broadcast 流进行广播,这样在每个 TaskManager 中会有一份商品详情数据,订单流就可以直接查询 broadcast 的数据,不需要再访问 MySQL 数据库来做查询操作。
那么具体要怎么实现呢?其实也很简单,可以看下面这段代码
1 | MapStateDescriptor<String, Product> productStateDescriptor = |
拿到 BroadcastConnectedStream 之后,我们就可以调用 process 方法进行处理了。完整的代码我放到 GitHub 上了。感兴趣的可以查看。
在使用 Broadcast State 的时需要注意,目前 RocksDB 不支持保存 Broadcast State,因此,广播流吞吐量必须要小,并且 Flink 任务要预留足够的内存。
聊完了 Broadcast State,我们再来看看 Operator State 是如何进行重新分布的。正常 Operator State 支持两种重新分布的方式,按照不同的方式,我们可以划分为 ListState 和 UnionListState。
ListState:所有的 element 均匀分布到 task 上
UnionListState:每个 element 都要在所有的 task 上
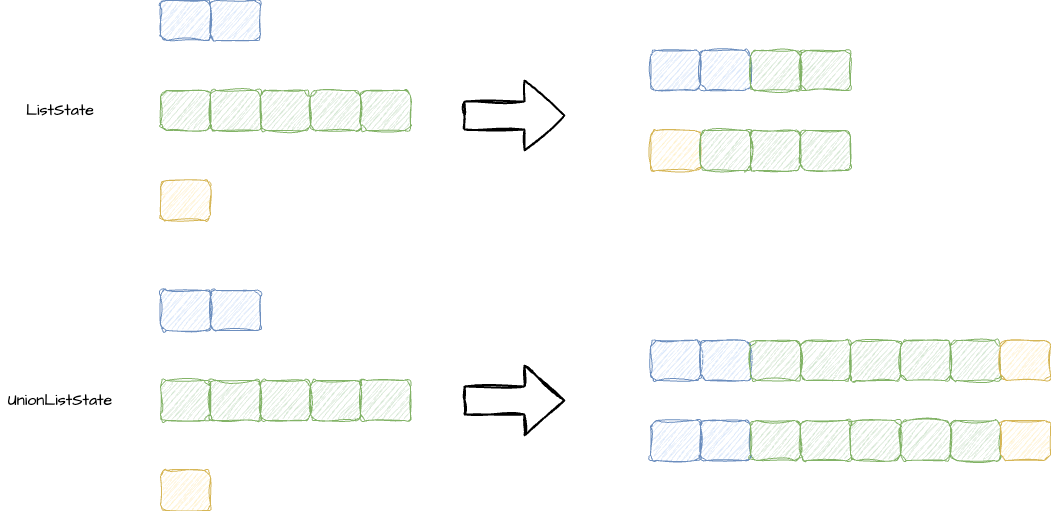
Broadcast State 由于本身就是广播状态,因此重新分布后仍然是需要进行广播的。
状态有效期
最后再来扩展一个知识点,就是状态的有效期。在 Flink 中,只有 Keyed State 支持有效期。具体使用方法如下。
1 | StateTtlConfig ttlConfig = StateTtlConfig |
这里有三个属性,我们分别来解释一下,首先第一个是过期时间,在调用 newBuilder 时就要传入。
第二个是 UpdateType,也就是更新策略,默认是 OnCreateAndWrite,表示在创建和写入时更新,也可以设置为 OnReadAndWrite,表示在读取和写入时更新。
第三个是可见性,默认是 NeverReturnExpired,即不返回过期数据,也可以设置为 ReturnExpiredIfNotCleanedUp,表示会返回过期但未被清理的数据。
状态数据清理策略也分为两种:一种是做全量快照时进行清理,创建 ttl 时调用 cleanupFullSnapshot() 方法即可。
另一种是增量数据清理,在访问或处理状态时,状态后端保留一个所有状态的惰性迭代器,每次清理时选择已经过期的数据进行清理。设置方法时在创建 ttl 时调用 cleanupIncrementally(10, true) ,可以看到它提供两个参数,第一个参数是设置每次检查的条数,默认是5。第二个参数是是否在处理每条记录时都触发清理,默认是 false。
总结
最后我们来总结一下,本文我们主要介绍了 Flink 的状态及应用,首先介绍有状态计算的概念。接着重点学习了 Keyed State 和 Operator State。我们通过一个表格来进行总结。
| Keyed State | Operator State | |
|---|---|---|
| 使用算子类型 | 只能被用于 KeyedStream 中的Operator 上 | 可以被用于所有 Operator |
| 状态分配 | 每个 Key 对应一个状态,单个 Operator 中可以包含多个 Key | 单个 Operator 对应一个状态 |
| 创建和访问方式 | 重写 RichFunction,通过访问 RuntimeContext 对象获取 | 实现 CheckpointedFunction 或 ListCheckpointed 接口 |
| 横向拓展 | 状态随着 Key 自动在多个算子 Task 上迁移 | 有多种重新分配的方式:均匀分布。将所有状态合并再分发到每个实例上 |
| 支持数据类型 | ValueState, ListState, ReducingState, AggregatingState, MapState | ListState, UnionListState, Broadcast State |
最后,我们又介绍了状态有效期的定义和使用方法。有了状态之后,Flink 就可以为我们提供非常强大的容错能力了,具体怎么做的我们后面再聊。