Flink学习笔记:多流 Join
前面我们已经了解了 Flink 几个核心概念,分别是时间、Watermark 已经窗口。今天我们来一起了解下 Flink 是怎么进行多个流的 Join 的。
我们今天从两个流的 Join 来入手,扩展到多个流也是一样的道理。Flink 中的 Join 可以分为两种:Window Join 和 Interval Join。
Window Join
Window Join 是将两个流中在相同窗口中且有相同 key 的元素进行关联。关联后,可以使用 JoinFunction 和 FlatJoinFunction 进行处理。Window Join 可以根据窗口类型分为三种:Tumbling Window Join、Sliding Window Join 和 Session Window Join。
Tumbling Window Join
首先来看Tumbling Window Join,其实就是对应的使用滚动窗口进行 Join。

具体使用方法如下:
1 | DataStream<Tuple2<String, Double>> result = source1.join(source2) |
其中 source1 和 source2 分别代表两个流,where 为 source1 的 join key 提取方法,equalTo 为 source2 的 join key 提取方法,最后,join 好之后的数据通过 JoinFunction 来处理。
Sliding Window Join
Sliding Window Join 和 Tumbling Window Join 的用法基本一致,只是将窗口指定为滑动窗口。
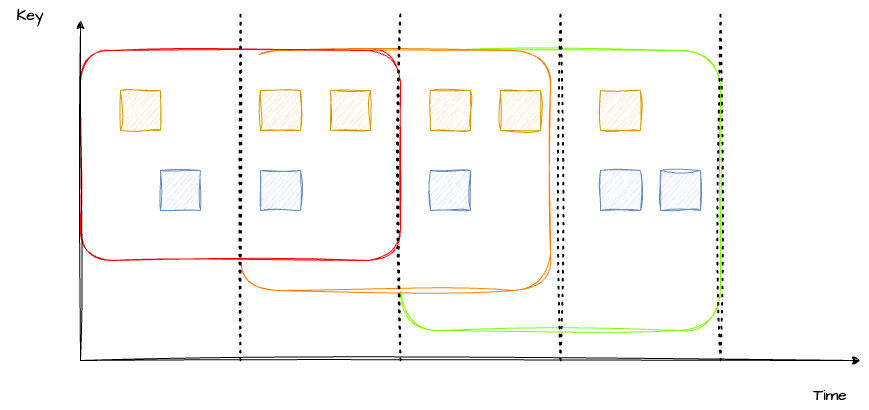
Session Window Join
Session Window Join 也类似,只是指定的窗口不同,具体的处理流程都是一样的,这里也不过多解释。
Interval Join
Interval Join 是将两个流中 key 相同,且一个流的 timestamp 处于另一个流的 timestamp 上下波动范围内。
假设我们有两个流 a 和 b,Interval Join可以表达为b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound] 或 a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound。
需要注意的是,目前 Interval Join 仅支持 event time。

它的使用方法也很简单,只需要定义上下偏移量以及处理函数即可。
1 | DataStream<Tuple2<String, Double>> intervalJoinResult = source1.keyBy(record -> record.f0) |
CoGroup
前面介绍的两种 Join 都是 inner join,那么 Flink 有没有办法支持 left join 呢?答案是肯定的,我们可以使用 coGroup 来实现。
coGroup 的通用用法如下:
1 | stream.coGroup(otherStream) |
我们通过自定义 CoGroupFunction 来实现 left join。
1 | private static class LeftJoinFunction implements CoGroupFunction<Tuple2<String, Double>, Tuple2<String, Double>, Tuple2<String, Double>> { |
在 coGroupFunction 中,需要实现 coGroup 方法,方法的参数包括两个输入流的 Iterable 和输出的 collector。如果第二个流中没有匹配的元素,那么就直接输出第一个流的元素。
总结
最后来总结一下,Flink 中有两种 Join 方法,分别为 Window Join 和 Interval Join,Window Join 是依赖窗口来执行,对窗口内的元素进行 join,Interval Join 不依赖窗口,是根据 event time 的范围来进行 join。最后还介绍了 CoGroup,我们可以使用 CoGroup 来实现 left join 和 right join。