Flink学习笔记:整体架构
开一个新坑,系统性的学习下 Flink,计划从整体架构到核心概念再到调优方法,最后是相关源码的阅读。
今天就来学习 Flink 整体架构,我们先看官网的架构图
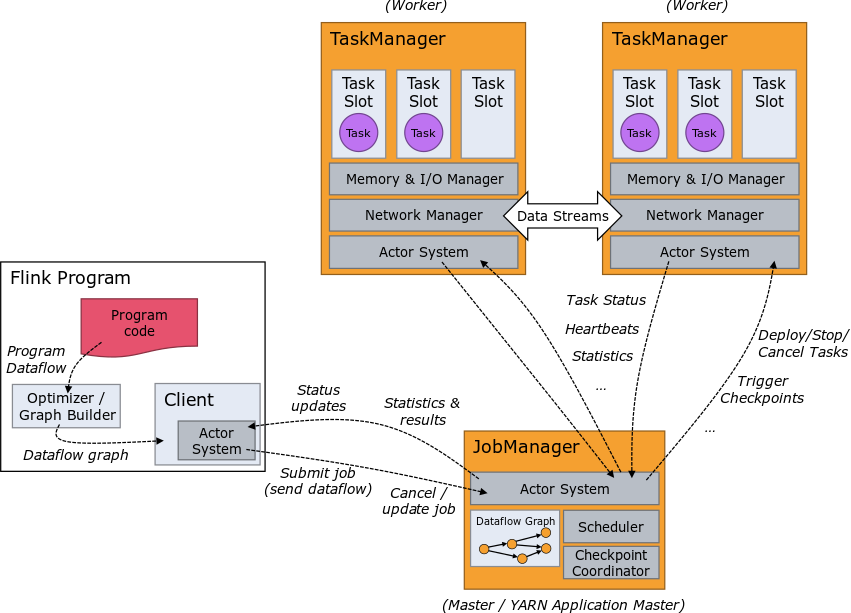
图中包含三部分,分别是 Client、JobManager 和 TaskManager。其中 Client 并不属于 Flink 集群,它主要用来把用户编写的程序翻译成 StreamGraph 然后优化成 JobGraph,再将 JobGraph 提交到 Flink 集群执行。
JobManager
Flink 集群的 JobManager 是用来接收 Client 提交的任务,并且分发给 TaskManager 去执行。此外,JobManager 还有一些其他的职责,例如任务调度,协调 checkpoint 和协调从失败中恢复。
每个 Flink 集群至少要有一个 JobManager,但在生产环境中通常是高可用模式部署,即部署多台 JobManager,其中一台作为 Leader,其他的作为 Standby 节点。当 Leader 挂掉时,其他的 Standby 节点会有一台被选举为新的 Leader 提供服务。这样就能避免 JobManager 单机故障影响到整个 Flink 集群的可用性。
JobManager 主要由以下几部分组成,下面我们分别来看每部分的作用。
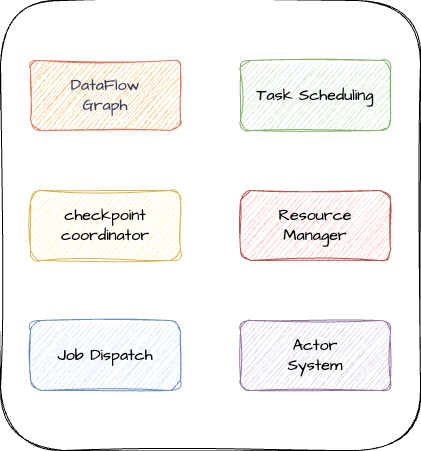
DataFlow Graph
JobManager 收到 JobGraph 之后,根据并行度的设置,将各个算子任务拆分成并行的子任务,最终生成 ExecutionGraph。
Checkpoint coordinator
Checkpoint 是 Flink 最核心的概念之一,Flink 的容错机制主要靠 checkpoint 来保障。而 checkpoint 的生成会恢复则由 checkpoint coordinator 来负责。
Job Dispatch
Job Dispatch 提供了 REST 接口用于提交 Flink 任务,并为每个任务启动一个 JobMaster。JobMaster 负责管理单个 JobGraph 的执行。
Task Scheduling
Task Scheduling 负责 Task 部署和调度,值得一提的是,JobManager 和 TaskManager 以及 Client 之间的通信都是通过一个叫 Actor System 的 RPC 系统实现的。
Resource Manager
Resource Manager 负责集群中的资源的分配回收,它管理的资源单元叫做 task slot,对于不同的部署环境,Resource Manager 有不同的实现,
Actor System
Actor System 是 Flink 集群中的一种 RPC 通信的组件,JobManager 和 TaskManager 以及 Client 之间的通信都是基于 Actor System 的。而 TaskManager 之间的数据传递是基于 Netty 的。
TaskManager
聊完了 JobManager,我们再来看下 TaskManager 的结构。TaskManager 主要负责执行作业的 task,并缓存和交换数据流。TaskManager 中最小的资源调度单位是 task slot,这点在前面介绍 Resource Manager 时也提到过。它表示并发处理 task 的数量。
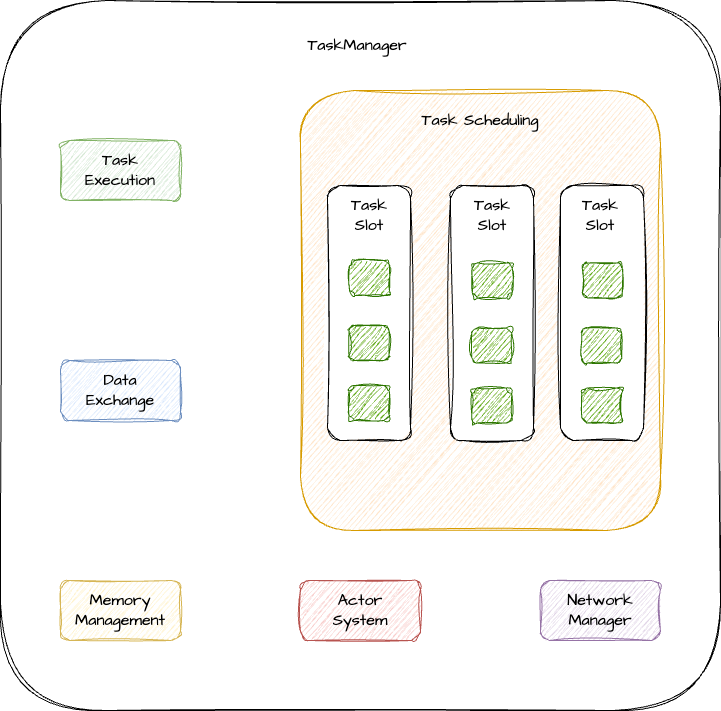
Task Execution
TaskManager 在接到 JobManager 部署的任务后,就会申请相应的 task slot 去执行任务。
Data Exchange
Data Execution 主要负责 TaskManager 之间的数据交互的一些操作,这里主要关注逻辑层面,例如一些 shuffle 操作。而网络传输则主要是由 Network Manager 来实现。
Memory Management
Memory Management 负责 TaskManager 的内存管理,在执行任务过程中,接收到的一些数据是需要放在内存中进行处理的。相应的内存管理操作依赖于 Memory Management 模块。
Actor System
Actor System 我们在前面提到过,TaskManager 和 JobManager 之间的通信全靠它。
Network Manager
Network Manager 主要负责 TaskManager 之间的数据交互,它是基于 Netty 实现的。
最后多提一个 Graph 的概念,前面我们已经了解到了 JobManager 会将 JobGraph 根据并行度的配置转换成 ExecutionGraph。在这之后,JobManager 会对作业进行调度,将 task 部署到各个 TaskManager 上,最终就形成了物理执行图,也就是 PhysicalGraph。
这里小结一下,Flink 中四种图的生成顺序是:用户编写的代码生成 StreamGraph,Client 将其进行优化,主要是将多个符合条件的节点 chain 在一起,生成了 JobGraph,然后将 JobGraph 提交到 JobManager,再由 JobManager 生成并行版本的 ExecutionGraph,待JobManager 将 task 调度后,生成的图被称为 PhysicalGraph。
Flink 的几种部署模式
根据集群的生命周期、资源隔离以及 main() 方法的执行,通常将 Flink 的部署模式分为三种:Session Mode、Per-Job Mode 和 Application Mode。下面我们分别介绍这三种部署模式。
Session Mode
Session Mode 下,所有的任务共享 JobManager 和 TaskManager,JobManager 的生命周期不受提交的 Job 影响,会长期运行。
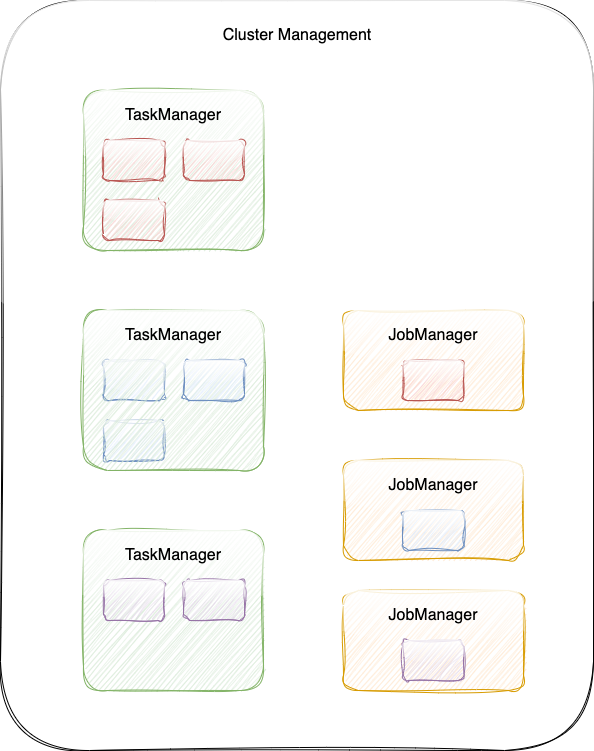
Per-Job Mode
Per-Job Mode 下,每个任务独享 JobManager 和 TaskManager,资源充分隔离。JobManager 的生命周期和 Job 的生命周期绑定。
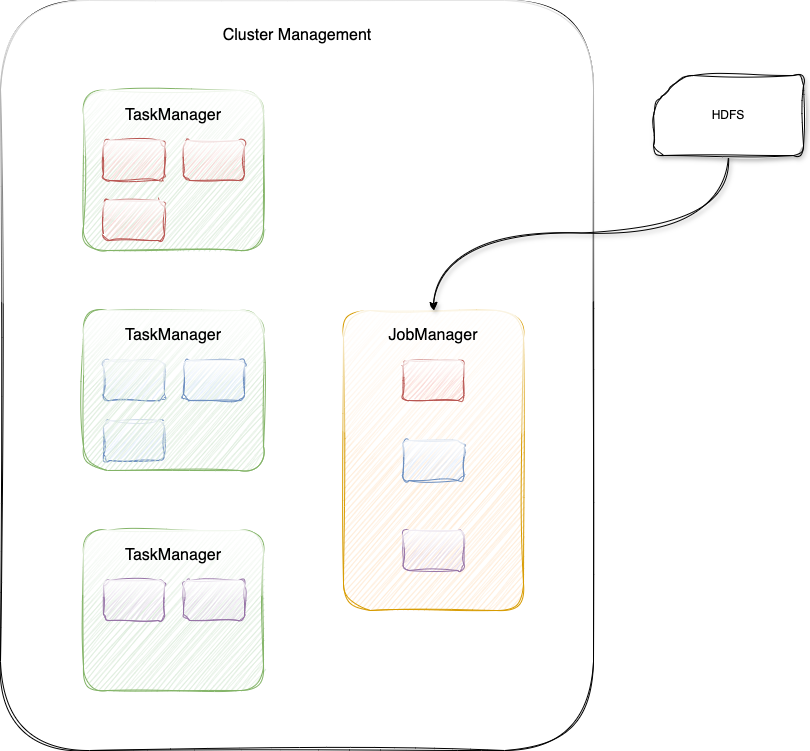
Application Mode
Application Mode 下,每个 Application 对应一个 JobManager,且可以运行多个作业。客户端无需将依赖包上传到 JobManager,只负责提交作业,减轻了客户端的压力。提交作业后,JobManager 主动从 HDFS 拉取依赖包。
三种模式的对比
| Session | Per-Job | Application | |
|---|---|---|---|
| 优点 | 1、资源充分共享,提升资源利用率 2、作业集中管理,运维简单 |
1、资源充分隔离 2、每个作业的 TM Slots 可以不同 |
1、有效降低带宽和客户端负载 2、Application 之间实现资源隔离,Application 中的资源共享 |
| 缺点 | 1、资源隔离差 2、TM 不易扩展,伸缩性差 |
1、资源浪费 | 1、仅支持 Yarn 和 Kubunetes (个人感觉够用了) |
总结
最后来总结一下,今天主要学习了 Flink 的整体架构和三种部署模式。
1、Flink 的集群架构上主要包含 JobManager 和 TaskManager,其中 JobManager 主要负责一些作业调度和资源协调的工作,TaskManager 则主要负责执行任务。
2、Flink 的部署模式分为 Session、Per-Job 和 Application 三种,Session 模式是所有 Job 共享 JobManager 和 TaskManager,Per-Job 则是作业独享的,而 Application 模式则是在 Application 中共享 JobManager。