经过前面对Redis源码的了解,令人印象深刻的也许就是Redis各种节约内存手段。而Redis对于内存的节约可以说是费尽心思,今天我就再来介绍一种Redis为了节约内存而创造的存储结构——压缩列表(ziplist)。
存储结构
ziplist是zset和hash在元素数量较少时使用的一种存储结构。它的特点存储于一块连续的内存,元素与元素之间没有空隙。我们可以用DEBUG OBJECT命令来查看一个zset的编码格式:
1 | 127.0.0.1:6379> ZADD db 1.0 mysql 2.0 mongo 3.0 redis |
那么ziplist究竟是一种怎样的结构的,话不多说,直接看图。
ZIPLIST OVERALL LAYOUT
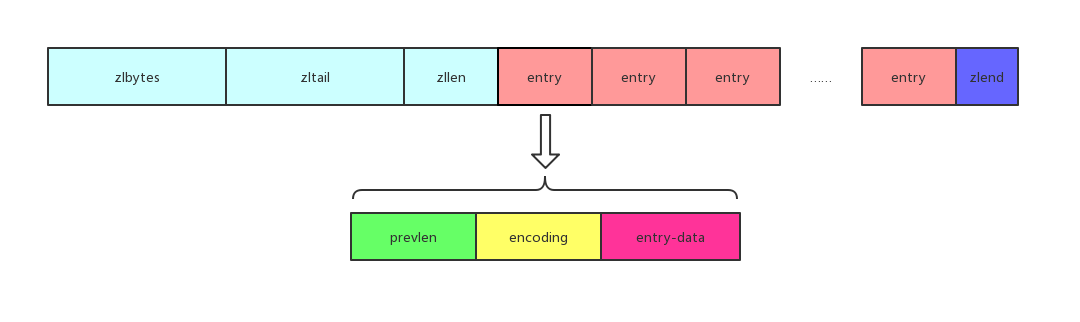
接下来我们挨个解释一下每一部分存储的内容:
- zlbytes:32位无符号整数,存储的是包括它自己在内的整个ziplist所占用的字节数
- zltail:32位无符号整数,存储的是最后一个entry的偏移量,用来快速定位最后一个元素
- zllen:16位无符号整数,用于存储entry的数量,当元素数量大于216-2时,这个值就被设置为216-1。我们想知道元素的数量就需要遍历整个列表
- entry:表示存储的元素
- zlend:8位无符号整数,用于标识整个ziplist的结尾。它的值是255。
ZIPLIST ENTRIES
了解了ziplist的大概结构以后,我们剖析更深一层的entry的结构。
对于每个entry都有两个前缀
- prevlen:表示前一个元素的长度,它与zltail字段结合使用可以实现快速的从后向前定位元素
- encoding:表示元素的编码格式,它用来表示元素是整数还是字符串,如果是字符串,也表示字符串的长度
- entry-data:元素的数据,它并不是一定存在,对于某些编码而言,编码本身也是数据,因此这一部分可以省略
这里要解释一点,prevlen是一个变长的整数,当前一个元素的长度小于254时,它仅需要一个字节(8位无符号整数)表示,如果元素的长度大于(或等于)254字节,prevlen就用5个字节来表示,其中第一个字节是254,后4个字节表示前一个元素的长度。
encoding字段决定了元素的内容。如果entry存储的是字符串,那么就通过encoding的前两位来区分不同长度的字符串,如果entry存储的内容是整数,那么前两位都会被设置为1,再后面两位用来区分整数的类型。
- |00pppppp|:字符串长度小于63字节,pppppp是6位无符号整数,用来表示字符串长度
- |01pppppp|qqqqqqqq|:字符串长度小于等于16383字节,后面14位表示字符串长度
- |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt|:字符串长度大于等于16384字节,后4个字节表示字符串长度
- |11000000|:16位整数,后面跟2个字节存储整数
- |11010000|:32位整数,后面跟4个字节存储整数
- |11100000|:64位整数,后面跟8个字节存储整数
- |11110000|:24位整数,后面跟3个字节存储整数
- |11111110|:8位整数,后面跟1个字节存储整数
- |1111xxxx|:(xxxx 取值从0000到1101)表示0到12的整数,读到的xxxx减1为实际表示的整数。这就是前面提到的省略entry-data的情况
- |11111111|:ziplist的结束值,也就是zlend的值
说了这么多,也许你还是不太清楚ziplist存储的内容究竟要表示什么,我们还是来举一个栗子
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]
这是一个实际的ziplist存储的内容,我们就一起来解读一下。
首先是4个字节的zlbytes,ziplist一共是15个字节,因此zlbytes的值是0x0f;接下来是4个字节的zltail,偏移量是12,因此zltail的值是0x0c;后两个字节是zllen,也就是一共两个元素;第一个元素的prevlen为00,0xf3表示元素值是2:1111 0011符合上述第9条,读到xxxx为3,需要减1,因此实际值是2;第二个元素同理,0xf6表示的值是5,最后0xff表示这个ziplist结束。
这时,我向这个ziplist中又加了一个元素,是一个字符串,请大家自行解读下面的entry(注意,只是entry)。友情提示:需要查询ASCII码表来解读
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
增加元素
了解了ziplist的存储之后,我们再来看一下ziplist是如何增加元素的。前面提到过,ziplist存储结构用于元素数量少的zset和hash。那么我们就以zset为例,一起追踪源码,了解ziplist增加元素的过程。
我们从ZADD命令执行的函数zaddCommand()开始。
1 | void zaddCommand(client *c) { |
它只是简单调用了zaddGenericCommand()函数,传入了客户端对象c和一个标志位,表示要执行ZADD命令,因为这个函数同样也是ZINCRBY要执行的函数(传入的标志是ZADD_INCR)。
而在zaddGenericCommand()函数中,首先对参数进行了处理,并且做了一些校验。
1 | /* Lookup the key and create the sorted set if does not exist. */ |
然后判断key是否存在,如果存在,验证数据类型;否则创建一个新的zset对象。这里可以看到,当
zset_max_ziplist_entries为0或者第一个元素的长度大于zset_max_ziplist_value时,创建zset对象,否则创建ziplist对象。创建好对象之后,就开始遍历元素,执行zsetAdd函数了:
1 | for (j = 0; j < elements; j++) { |
这个函数用来增加新元素或者更新元素的score。这个函数中判断了zset对象的编码方式,对压缩列表ziplist和跳跃列表skiplist分开处理,跳跃列表是zset的另一种编码方式,这个我们以后再介绍,本文我们只关注ziplist。
1 | if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { |
可以看到,这里首先调用zzlFind()函数查找对应的元素,如果元素存在,那么就判断是否包含参数NX或者是否是INCR操作。如果修改了元素的分数,则先删除原有的元素,再重新增加;如果元素不存在,就直接执行zzlInsert()函数,再insert之后,会判断是否需要改为跳跃列表存储。这里有两个条件:
- zset元素数量大于zset_max_ziplist_entries(默认128)
- 添加的元素长度大于zset_max_ziplist_value(默认64)
满足任意一个条件,zset都会使用跳跃列表来存储。
我们继续追踪zzlInsert()函数。
1 | unsigned char *zzlInsert(unsigned char *zl, sds ele, double score) { |
它首先定位了zset的第一个元素,如果该元素不为空,就比较该元素的分数s与要插入的元素分数score,如果s>score,就插入到当前位置,如果分数相同,则比较元素(按字典序)。插入后,将后面的元素依次移到下一位。
1 | unsigned char *zzlInsertAt(unsigned char *zl, unsigned char *eptr, sds ele, double score) { |
在zzlInsertAt()函数中,主要是调用了ziplistPush()或者ziplistInsert()将元素和分数插入列表尾部或中间。插入顺序是先插入元素,然后插入分数。
接下来就到了ziplist.c文件中,真正向压缩列表中插入元素了。关键代码在__ziplistInsert()函数中。
首先需要计算插入位置前一个元素的长度,存储到当前entry的prevlen。
1 | if (p[0] != ZIP_END) { |
这里区分了是否是在尾部插入元素的情况,如果是在尾部,就可以通过ziplist中的zltail字段直接定位。接下来就是尝试对插入的元素进行编码,判断是否可以存储为整数,如果不能,就按照字符串的编码格式来存储。
1 | if (zipTryEncoding(s,slen,&value,&encoding)) { |
这一步判断是节省内存的关键,它会使用我们前面介绍的尽量小的编码格式来进行编码。编码完成后就要计算当前entry的长度,包括prevlen、encoding和entry-data,并且需要保证后一个entry(如果有的话)的prevlen能够保存当前entry的长度。这里调用的是zipPrevLenByteDiff()函数,需要的prevlen的长度和现有的prevlen的长度的差值,也就是说如果返回为整数,表示需要更多空间。
在这之后就要调用zrealloc()来扩展空间了。这里有可能会在原来的基础上进行扩展,也有可能重新分配一块内存,然后将原来的ziplist整体迁移。如果ziplist占用较大内存时,整体迁移的代价是很高的。有了足够的空间之后,就是把当前位置的entry向后移一位了,然后要修改这个entry的prevlen。更新zltail。
1 | if (nextdiff != 0) { |
nextdiff是前面zipPrevLenByteDiff()函数的返回值,它不为0表示需要更多空间(小于0时被置为0)。这时后面的元素需要级联更新。所有的这些处理完毕之后,我们终于可以把要插入的entry写入当前位置了,并且将ziplist的长度加1。
级联更新
如果一个entry的长度小于254字节,那么后一个元素的prevlen就用一个字节来存储,否则就要用5个字节存储。当我们插入一个元素时,如果它的长度大于253字节,那么原来的entry就可能从1个字节变成5个字节,而如果由于这一变化导致这个entry的长度大于254字节,那么后面的元素也要更新。到后面甚至有可能导致重新分配内存的问题,所以级联更新是一件很可怕的事情。
接下来就通过源码,看一下级联更新的具体步骤。(查看ziplist.c文件的__ziplistCascadeUpdate函数)
首先,判断当前entry是否是最后一个,如果是,则跳出级联更新。
1 | if (p[rawlen] == ZIP_END) break; |
接着判断了下一个entry的prevlen长度是否发生变化,如果没有变化,也不用继续进行级联更新。
1 | if (next.prevrawlen == rawlen) break; |
而如果下一个entry的prevlen长度需要扩展,那么就先调用ziplistResize扩展内存,然后要更新zltail。要将后面的entry向后移动,再开始判断下一个entry是否需要更新。
1 | if (next.prevrawlensize < rawlensize) { |
如果后面的entry的prevlen大于需要的长度呢,此时应该收缩prevlen,如果要进行收缩,那么可能会继续级联更新。这太麻烦了,所以这里选择了浪费一些空间,用5个字节的空间来存储1个字节可以存储的内容。如果prevlen的长度等于需要的长度,就直接更新内容。
1 | if (next.prevrawlensize > rawlensize) { |
除了新增操作以外,删除操作也有可能引起级联更新。假设我们有3个entry是下面的情况
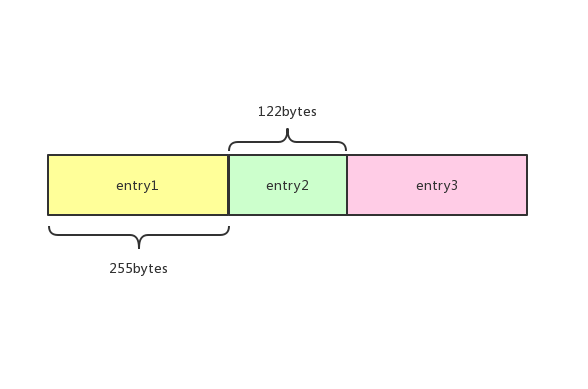
我们可以知道,entry2的prevlen需要5个字节,entry3的prevlen只需要1个字节。而如果我们删除了entry2,那么entry3的prevlen就需要扩展到5个字节,这一操作就有可能引起级联更新,后面的情况和新增节点时一样。
总结
最后做一个总结:
- 压缩列表是zset和hash元素个数较少时的存储结构
- ziplist由zlbytes、zltail、zllen、entry、zlend这五部分组成
- 每个entry由prevlen、encoding和entry-data三部分组成
- ziplist增加元素时,需要重新计算插入位置的entry的prevlen(prevlen的长度为1字节或5字节),这一操作有可能引起级联更新。


