volatile vs synchronized
今天来聊一聊Java并发编程中两个常用的关键字:volatile和synchronized。
在介绍这两个关键字之前,首先要搞明白并发编程中的两个问题:
- 线程之间是如何通信的
- 线程之间如何同步
Java内存模型
Java线程的通信由Java内存模型(JMM)控制,Java内存模型的抽象如图:
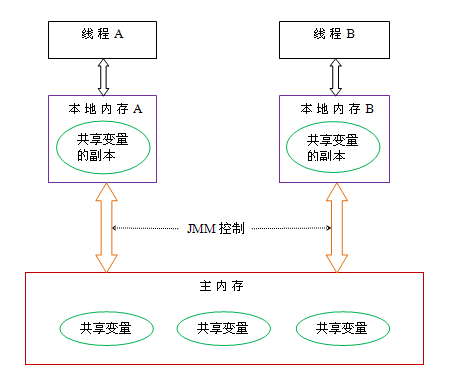
Java线程之间的通信总是隐式进行,通信过程对程序员完全透明。多个线程通过读-写共享内存来实现通信。
图中线程A与线程B通信的具体步骤是:
- 线程A把更新过的共享变量刷新到主内存中
- 线程B从主内存读取共享变量
例如,共享变量x的初始值为0,线程A将x修改为1(x=x+1),线程B读取到的x就是1,对于程序员来讲,就是线程A给线程B发消息说它把x的值更新为1。
第一个问题搞明白了,再思考一下第二个问题。线程之间如何同步?在并发编程中,有三个重要的概念:原子性、可见性、一致性。
原子性
在Java中,对基本数据类型的读取和赋值操作都属于原子操作。
1 | x = 10; |
上面两条语句中,第一句是原子操作,而第二句不是,为什么呢?实际上,第二句代码被编译为3条指令:
- 从内存中取x的值
- x+1操作
- 计算结果存入内存
可见性
当多个线程访问同一变量时,如果有一个线程修改了这个变量,那么其他线程立刻可以看到修改后的值。
有序性
CPU执行指令是按照先后顺序执行的,但是指令的顺序并不一定等同于代码的顺序,编译器编译过程中,为了提高性能,常常进行指令重排序。这种重排序不会改变单线程的语义,也就是说,你写的一段代码如果是单线程执行,编译器可能对执行进行重排序,但不论如何排序,最后得到的结果都是相同的。
另外,如果存在数据依赖性,编译器不会改变依赖关系的执行顺序。数据依赖性是指两个操作访问同一个变量,其中一个是写操作,那么这两个操作就有数据依赖性。
重排序对应多线程有哪些影响呢,我们通过一段代码来看一下:
1 | class ReorderExample { |
上述代码中,flag是变量a被初始化的标识,如果此时有两个线程A和B,A执行writer()方法,B执行reader()方法。由于1和2、3和4不存在数据依赖性,那么就有可能出现这种情况:
- A先执行语句2
- B执行了语句3和4
- A执行语句1
最终的结果并不是我们想要的,此时,重排序破坏了语义。
线程同步
对于上面所说的线程同步问题如何避免呢?可以使用Java中的volatile和synchronized这两个关键字。
volatile
volatile关键字比较轻量级,只可以修饰变量。volatile修饰的变量,如果值被更新,会立即刷新主内存,而读volatile修饰的变量时,JMM会把线程对应的本地内存置为无效,从主内存中读取。这样volatile就可以保证线程的可见性。
volatile关键字在一定程度上可以保证有序性:
- 当第二个操作是volatile写时,不能进行重排序
- 当第一个操作是volatile读时,不能进行重排序
- 当第一个操作是volatile写,第二个操作是volatile读时,不能重排序
为了实现这些语义,JMM采用屏障插入策略:
- 在volatile写操作前插入StoreStore屏障,后面插入StoreLoad屏障
- 在volatile读操作后面插入LoadLoad屏障和LoadStore屏障
也就是说,volatile写操作前的所有写操作都必须执行完,且需要等到volatile写操作执行后才能执行读操作。volatile读操作执行完之后才可以进行其他操作。也就是说volatile相当于一个屏障,其前面的操作不能放到volatile操作后面,后面的操作也不能放到volatile操作前面。
synchronized
synchronized比较重量级,可以用来修饰方法。synchronized关键字是给修饰对象加锁,只有获得锁的线程才可以执行,执行完后释放锁。因此synchronized保证了原子性和可见性。
文中图片来源于网络